LLM系统优化
论文一:Efficient Memory Management for Large Language Model Serving with PagedAttention
Introduction
当前大模型需要在GPU上占用大量的显存,其中有很大的一部分被用来存储模型的静态参数,这些参数会在大模型的服务期间保持不变。剩下的30%左右的空间被用来存储服务期间请求产生的动态的信息。这部分被叫做kv_cache。然而现有的kv_cache的空间管理系统存在两个主要的问题:
- 问题一:
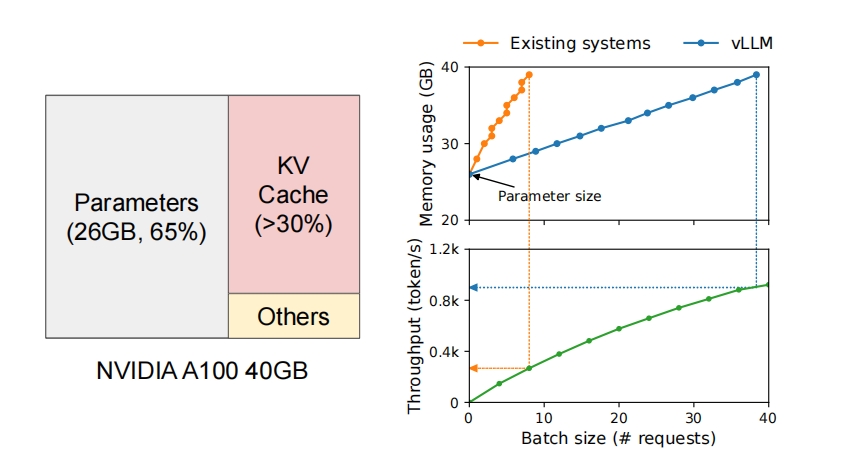
当前系统中需要把一个请求的kv cache放置在一个连续的存储空间之内,目前的做法是采用
预分配的方法(比如预先分配2048个token的空间),但在真实情况下,一个请求并不会使用所有的预分配空间,
这会导致严重的内存碎片化。此外我们能够在输入的时候知道一条request的长度,这种预分配的方式会导致我们预分配的空间在整个请求的生命周期中不能被别的请求所使用。
同时,在为每一条请求申请空间时,以chunk为单位的对齐方式的分配方式也不能够保证高效的空间分配。在测试中发现20.4%~38.2%的空间才被真正用来存储每条请求的数据。
- 问题二:
当前的系统设计不能够很好的利用内存共享。当前的大模型使用了多种解码算法,比如并行采样或者定向搜索。对于同一条请求的会生成多个outputs。然而对于一些解码结果,这些outputs是可以在不同的请求的kvcache之间进行共享的。但是由于现有的空间分配策略。每条request会独立存储自己的outputs,这回一定程度上带来kvcache的空间浪费。
为了解决以上的两个问题,作者提出pagedattention算法。该想法来源于擦偶哦系统的的虚拟内存以及页式管理策略。该算法通过把kvcache分割成以block为单位的空间。每一个block会包含attention keys & value以及固定长度的tokens。通过这样的方式能够把传统的操作系统和当前的llm中的定义进行联系起来。(blocks对应了操作系统的pages,tokens对应了操作系统的bytes,request对应了操作系统的进程)。
最终,算法实现了内存碎片的最小化,并且允许了以block为粒度的request内存共享机制。
Gitalk 加载中 ...