- 看了很多关于学习索引的文章,是时候探究一下他们的真实性能情况了。
文献阅读:Are Updatable Learned Indexes Ready?
这是一篇专门探究支持更新操作的学习索引性能的,也和我想要做的并发学习索引优化方向比较契合。
摘要
文章中通过使用了10个真实数据集和各种工作负载对当下主流的可更新学习索引的性能、内存开销和鲁棒性进行探究。
简介
性能评价层面。常见的学习索引评价标准是通过SOSD测试集进行的,但是人们大多只关注了在读操作性能,面对写操作性能,没有一个合适的评价标准。作者使用了PGM-index中使用的PLA算法模型把数据集通过两个维度进行评价。global hardness和local hardness,其中第一个参数反映了数据结构设计以及计算结构调整的开销函数;第二个参数反映了机器学习模型的准确率。
空间利用率层面。大部分的学习索引比传统的索引空间利用率要高许多。但是在这边文章中的测试中,在有的测试集上学习索引的空间利用率并没有那么令人满意。因此如何进一步提高学习索引的空间利用率还值得我们关注。
鲁棒性层面。面对可变化的数据负载,如何快速完成学习索引的重新学习也是需要关注的一个点。
学习索引技术
这里对原理不进行过多赘述,重点关注的是动态负载,当前的学习索引有三种处理方法。
使用树形合并。PGM-index使用了树型合并策略,这是来自于LSM树的灵感,简单来说就是先把插入的数据放在一个子集里面,超出容量了就扩大一倍,把数据放到下一层空间中,首先填满最上层的子集,上层子集满了之后才会往下层子集合并。这样能够保证数据的顺序性。
delta合并,这个是传统的数据库解决并发操作的设计,XIndex,FITing-Tree和FINEdex都使用了这个设计,主要是针对每个数据节点创建一个缓冲区来保存插入或者删除的数据,之后再进行周期性合并。唯一的设计上的区别就是力度大小不同。
使用稀疏的节点。ALEX,APEX,LIPP都是在数据节点中提前预留好了空位(LIPP是把预测到同一个位置的数据再开一个子节点保存,ALEX是通过节点分裂合并完成数据量增减),直接在数据节点上进行插入和删除操作,随之带来的数据结构上的改变(合并分裂等操作)会通过一个开销模型进行计算的。
此外,为了保证并发性,大部分学习索引都使用的是乐观锁。给每个数据节点赋值一个版本号,在读写请求之前都需要检查版本号。
测试环境搭建
LIPP和ALEX没有支持并发操作。作者直接对LIPP每个节点上了一个乐观锁,对于ALEX则是修改了APEX中在持久性内存上的并发部分代码。用来做对比的传统索引有STX B+-Tree、ART、HOT的单线程测试。对于多线程测试使用了B+-TreeOLC、ART-OLC、HOT-ROWEX、Masstree、Wormhole。全局非线性(误差值为4096)和局部非线性(误差值为32)共同构成了数据空间。全局非线性拟合效果不好代表了global hardness,局部非线性拟合效果不好代表了local hardness。
数据集前面四个来自于SOSD(这个是19年被提出来专门测试学习索引性能的测试集)。除了wiki,其余的负载都是8字节的无符号整数作为键。作者接下来给出了对数据集的评价标准。PLA模型其实就是保证线性预测模型预测误差在一个固定的误差范围内即可,如果超过了就进行分裂,创建一个新的模型来解决新的插入操作。给定一个数据集和误差,就可以计算出需要多少个线性回归模型。
测试结果呈现
- 单线程测试
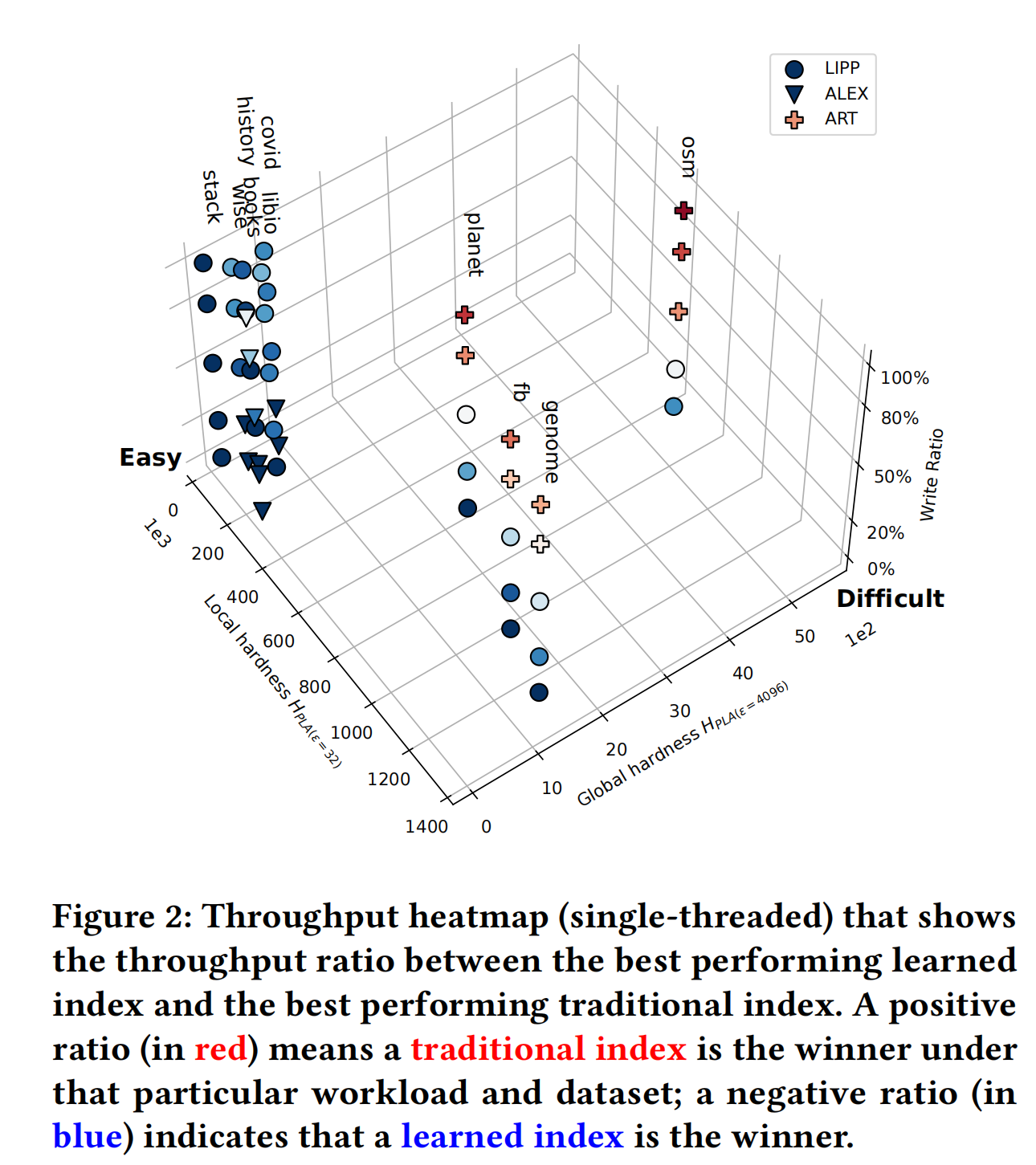
每个点代表了最好的学习索引吞吐量在相同情况下和最好的传统索引吞吐量的比例。蓝色点代表学习索引更好,红色的点代表了传统的索引更好,颜色越深代表提升的比例效果越好。通过图1可以看出在单线程情况下,80%以上的情况下可更新的学习索引性能要更好。大部分性能最好的是ALEX、LIPP和ART索引。严格来说PGM-index应该再100%写入操作下性能最好,这得益于类似LSM的插入合并策略。ALEX和LIPP性能如此突出的原因主要有两点,一个是使用机器学习解决节点内的的查找过程;二个是通过使用提前预留的空插槽解决了插入问题(值得注意的一点是相比于XIndex、FINEdex、PGM-Index这些使用delta buffer,空插槽避免访问在缓冲区中的各种树形结构)。第三点是在发生大量的写入操作的时候,学习索引性能相比传统索引会差很多。第四点是在读操作为主的测试中,学习索引会比传统学习索引要好很多,无论数据集的global hardness或是local hardness。
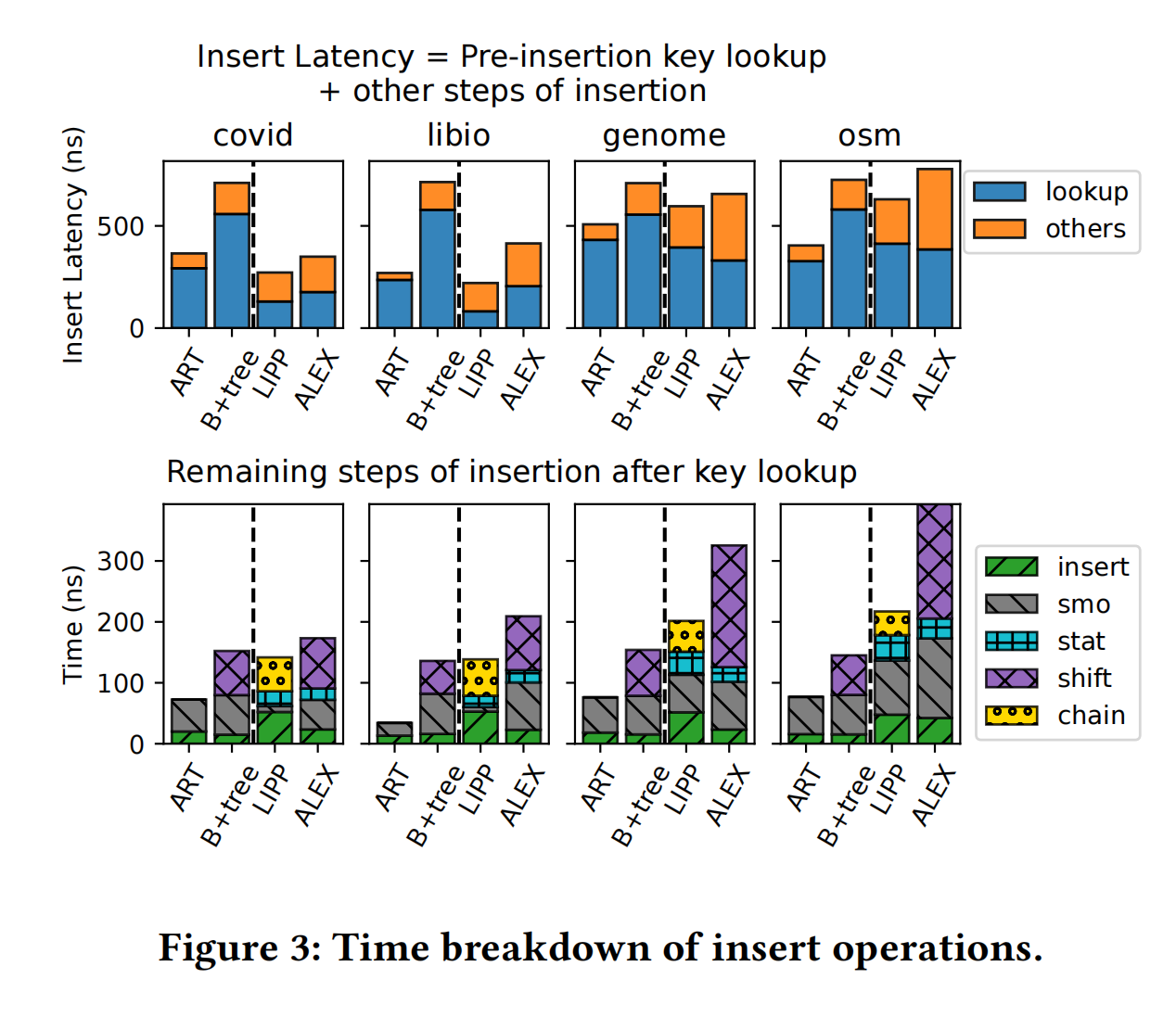
作者这里设计了一个新的实验。众所周知,插入操作首先需要在索引中进行查找,找到对应的插入位置后才能进行真正的插入操作。选取了最简单的两个负载covid和libio,local hardness最高的genome和global hardness最高的osm。除了osm负载,其他的负载环境下都有学习索引比传统索引更好。
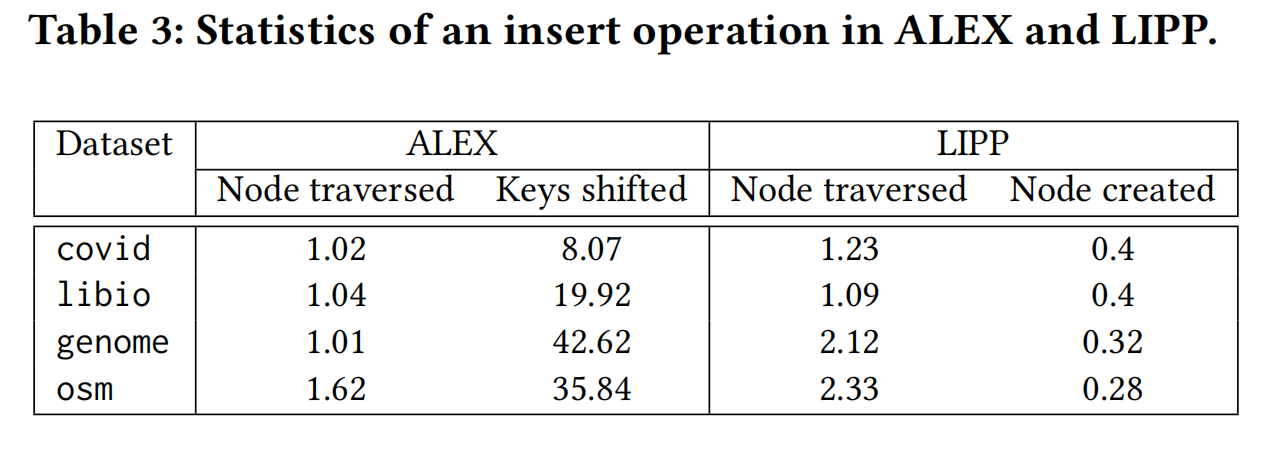
后续针对插入操作每个部分的延迟测试显示LIPP相比于ALEX有着更小的开销,原因是ALEX的在插入一个数据后的shifting操作会产生写放大。
- 多线程测试
使用24线程进行测试,最终的结果只有LIPP+,ALEX+和ART-OLC是性能最好的几个,但是LIPP在多线程的情况下,只有在读负载倾斜的情况下才会比ALEX+性能好一些。这是因为如果对单节点进行上锁,乐观锁需要更新整条路径上所有节点的版本。这会导致某些节点被长期占用,尤其是根节点。相比之下,ALEX使用无锁化查找并只对叶子节点进行上锁的策略就会好很多,直到ALEX的写放大成为性能瓶颈后贷款才不再上升。ALEX比XIndex和FINEdex性能都要好,这是十分有趣的,仅仅是把ALEX加入了一个乐观锁,就比专门解决并发的学习索引性能要好很多。
- NUMA影响
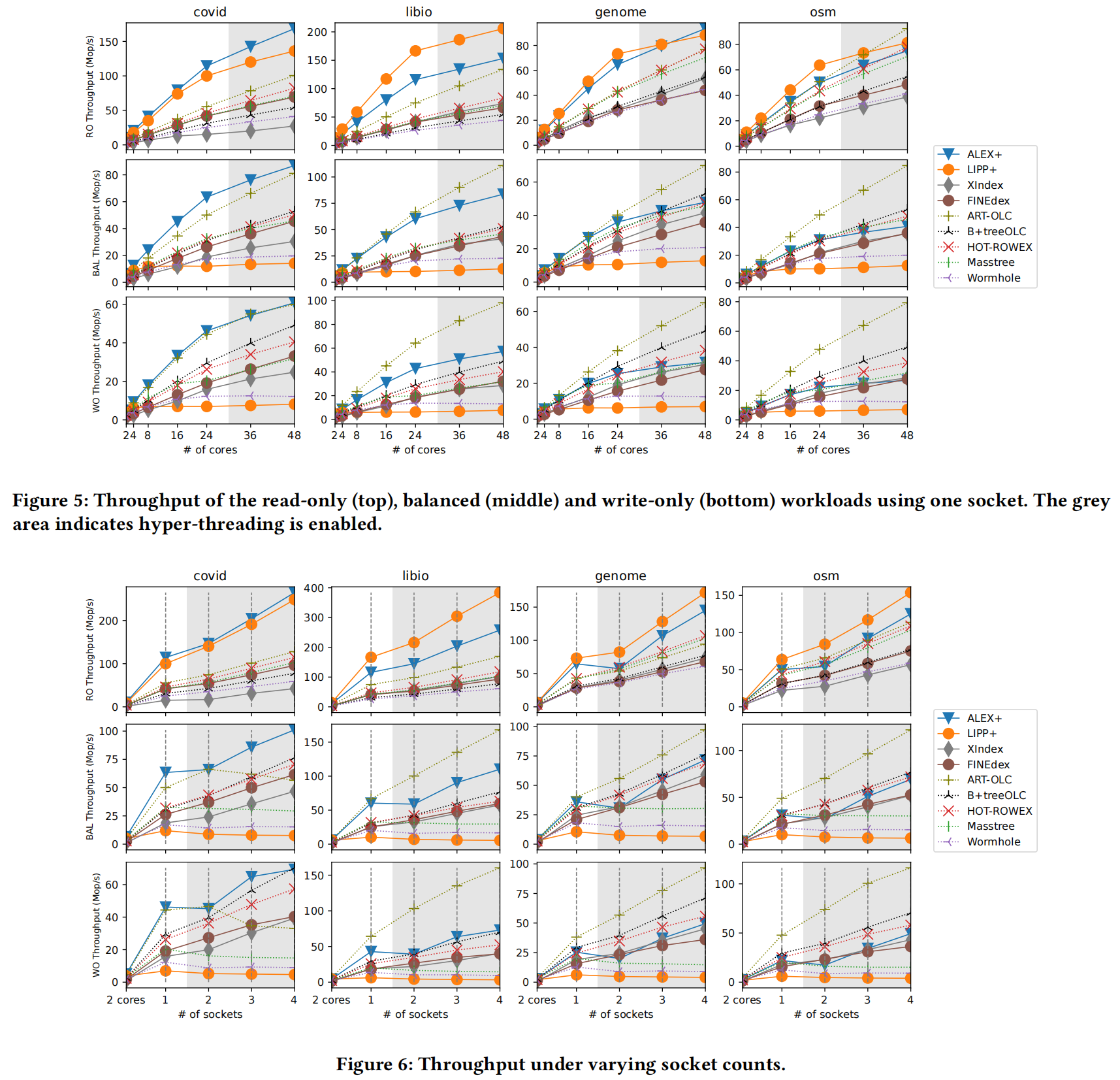
作者接下来对比测试了在不同读写比例下不同超线程数的吞吐量对比。LIPP+在有写操作的测试时直接不能产生性能提升,这点之前已经解释了原因。ALEX+在24线程下已经让内存饱和了。同时,测试了1到4个socket的扩展性。
- 删除操作性能
作者使用了200MB的数据集进行测试,删除一半的数据。基本上和单线程的测试结果相似。
- 内存空间使用率
最好的学习索引仅仅比最好的传统索引节约了3.2倍的空间开销,相比于HOT的空间开销也要大很多。ALEX是在节约空间的同时,性能最高的索引结构。,ART虽然使用了基数树作为存储结构,但是会产生很多的空指针,这会很占内存大小。LIPP的空间占用率要比ALEX大4~5倍,通过进一步探索,LIPP相比于ALEX是一种空间换时间的策略。
- 尾延迟
除了XIndex外,可更新的学习索引在单线程和多线程设置上都表现出较低的尾部延迟。然而,一些传统的索引(ART、HOT和b树)在这方面表现出了无可挑剔的鲁棒性。
- 更换数据分布
学习到的索引对数据分布的变化很敏感,而传统的索引则不太敏感。与之前的工作相一致,因此,一个预先填充了简单数据的学习索引要适应更难的数据集,就更难了。
- 范围查询
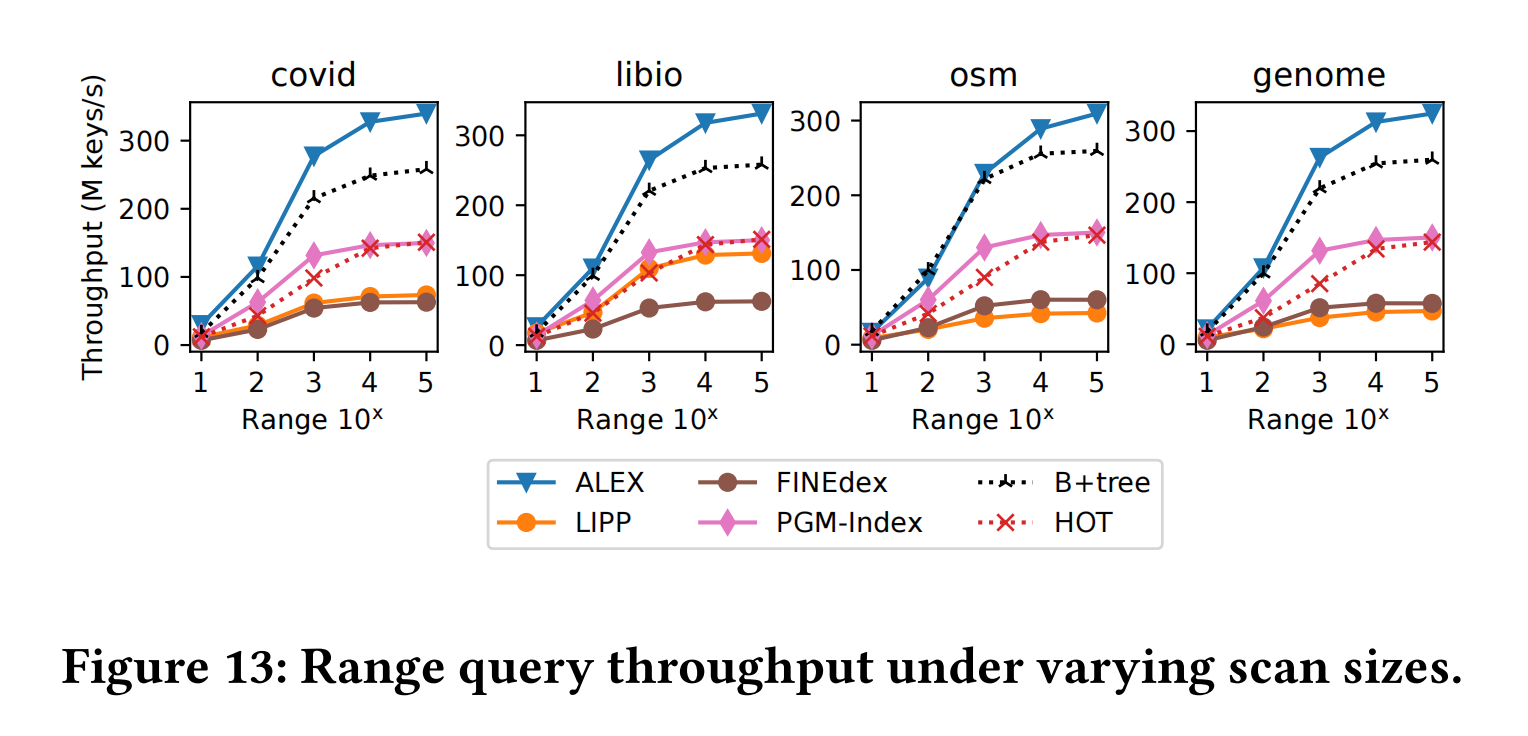
在范围查询表现上,学习索引有着很好的性能。LIPP和FINEdex却性能并不好,这是因为LIPP需要在范围查询的时候要进行分支预测决定访问哪个子节点。这里没有测试XIndex但是我猜想和FINEdex应该类似,都需要在范围查询的时候先去缓冲区找到按照顺序排好的数据,这就会产生很多额外的开销。
总结
使用机器学习模型对最底层数据节点进行查找以及使用稀疏节点处理插入操作很好的平衡了内存空间,性能和鲁棒性之间的关系。
要合理的设计测试数据集。
并发控制以及鲁棒性是学习索引首要解决的问题。
希望未来的学习索引能够考虑到缓存友好以及在NUMA场景下的性能。
目前的可更新的学习索引在内存消耗上并不占有很大的优势。
传统的索引结构还是有很大的亮点的。
思考与延伸
令人惊讶的是,虽然ALEX的设计已经出来两年了,但是人们对于可更新学习索引的研究却一直停滞不前。后续推出的XIndex和FINEdex无论是在单线程读写还是多线程读写性能上远远不如ALEX的并发控制版本。阅读上面这篇关于并发学习索引性能测试对比的文章也让我发现了每个设计结构的缺陷。这里想先谈谈自己在阅读过程中发现的问题。
首先是XIndex和FINEdex的设计有效性。XIndex是人们基于RMI模型进行的并发操作优化设计。传统的OLTP数据库索引(ICDE’2015)曾经设计了BW-tree,主要使用了两个策略:
- delta buffer:通过异地更新避免Cas操作一次只能更新一个地址上的数据,同时这样可以避免缓存失效。
- mapping table:实现了对物理页的Cas操作。
XIndex和FINEdex都想到了使用第一种delta buffer来解决并发操作。最大的区别是XIndex使用了B树(STX::Btree库),FINEdex使用了自己设计的一个两层的B树结构。另外一个区别是XIndex使用了两层RMI模型作为上层节点,FINEdex使用了使用了LPA模型(其实和PGM-index中的PLA一样,不知道为啥他这里作为了自己的创新点,这里作者添加了btree_opt选项)作为上层节点。这两种索引结构基本上代表了学习索引的两种数据结构策略,最终得到的测试结果也十分相近,在大部分场景下和b+树以及变种masstree性能不相上下(有一说一个人感觉这两个工作的价值不大)。在对比这几篇文章的测试结果时也发现了比较有趣的几点。
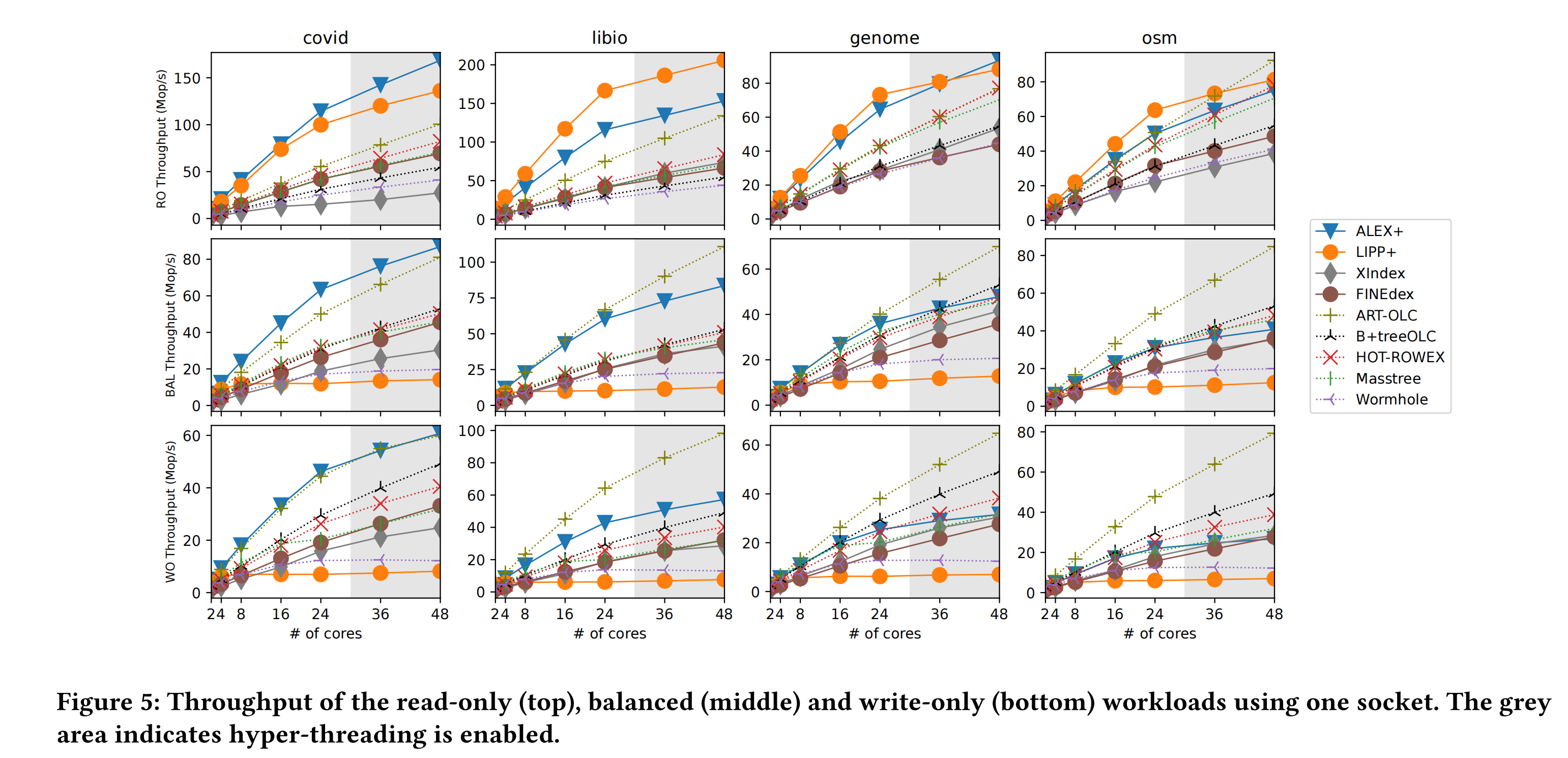
这是greindex对当下主流学习索引做的性能测试从上到下分别是只读,读写均衡和全写情况下的带宽,使用了单核24线程进行测试。
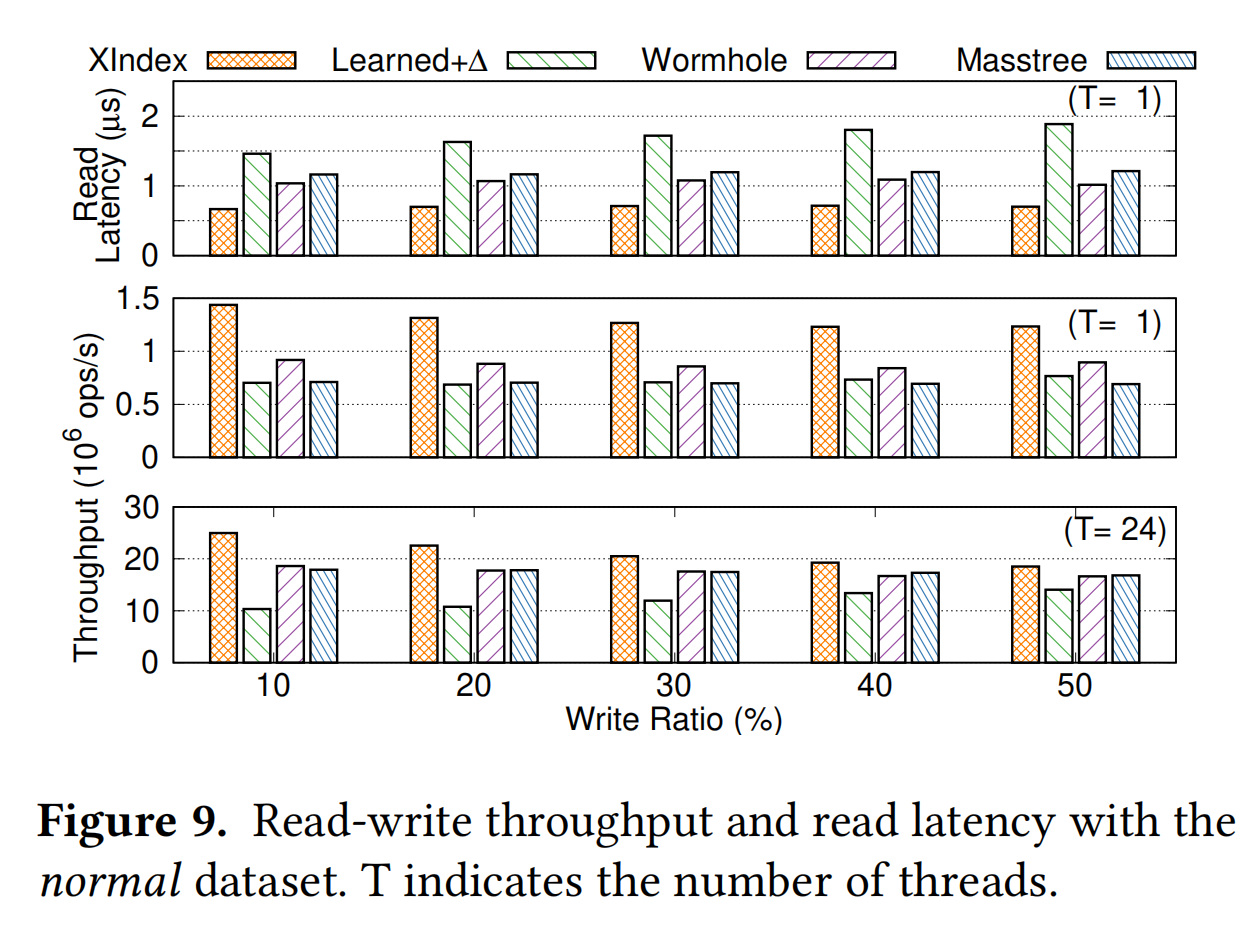
这是XIndex使用了双核24线程进行的测试,测试了在不同读写比例的情况下的带宽。可以看到除了XIndex以外的几种结构的带宽几乎没有下降的,怀疑是测试有问题。
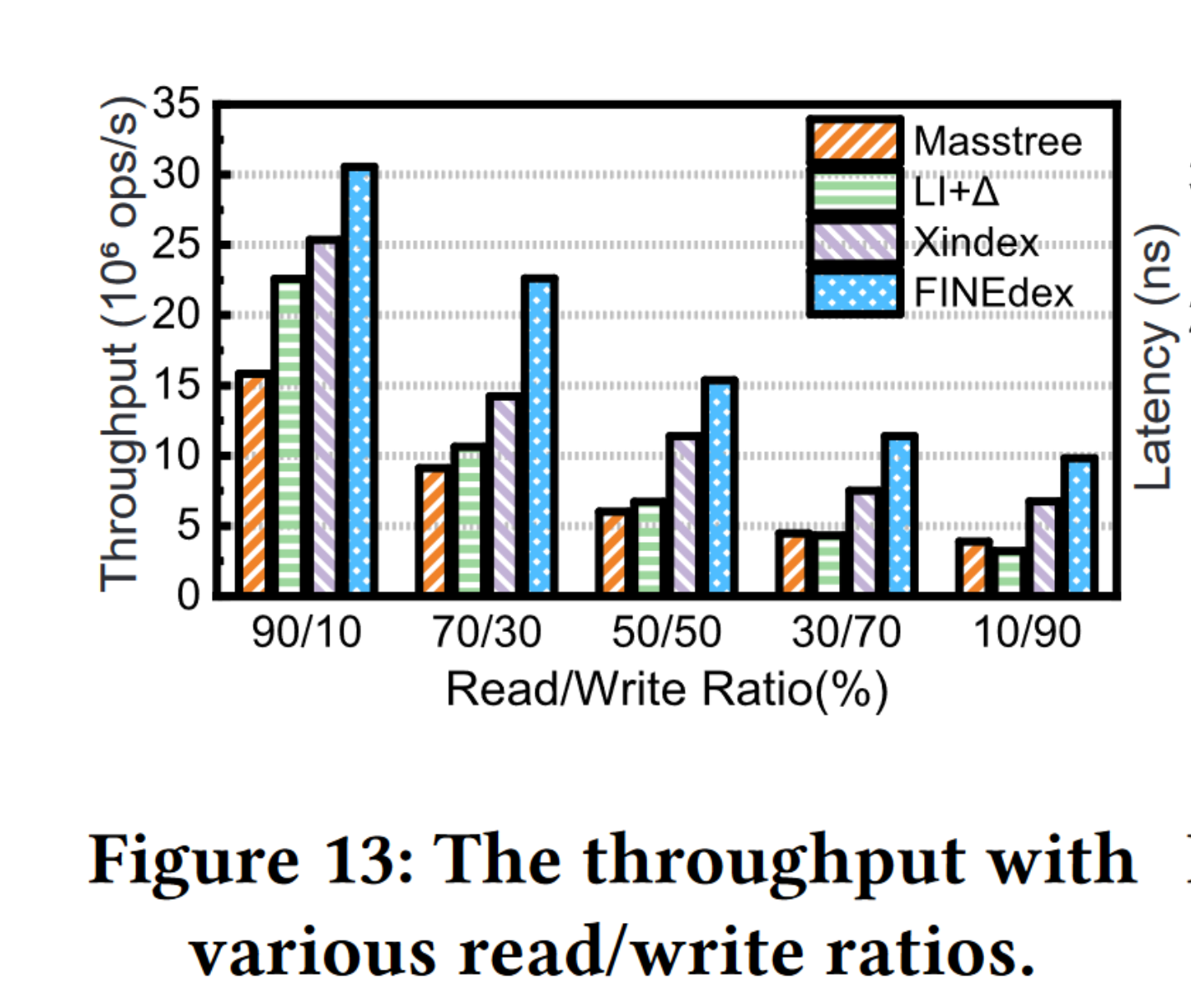
这是FINEdex使用单核24线程测试的结果。可以看到随着写比例的增加,LI+Δ的性能逐渐和Masstree相近,这一点也可以理解,因为LI+Δ本来就是使用了Masstree作为delta buffer。
此外,无论是XIndex还是FINEdex的测试都显示会比Masstree的性能要好很多,但是在greindex的测试中反映出来的并不是这样的,其实相比于ALEX和LIPP,FINEdex和XIndex两个设计主要输在了需要先把数据写到delta buffer,很多的数据访问就需要通过delta buffer来进行,因此无论在单线程还是多线程的情况下都要不如ALEX。
从上面的结果可以看到,使用稀疏数组来完成插入数据的解决方案是最好方案。其中最具有代表性的工作就是ALEX和LIPP,ALEX在并发情况使用了乐观锁机制,LIPP目前还没有特别好的并发控制解决方案,这是因为在发生并发操作的时候,LIPP更容易发生节点的分裂和合并操作。这里我们也可以总结出几条原则:
- 在并发情况下,尽量避免使用delta buffer这种解决方案(一个原因是需要在后续过程中进行模型重训练,另外在大量写操作情况下十分依赖delta buffer选区的数据结构)
- 在设计数据结构时,尽量避免设计出因为发生更新操作后需要频繁变化节点的数据结构(这一点在LIPP)。
- 使用乐观锁机制能够很好的减少锁资源开销(这个在NVM上也很常见,尤其是对以读操作为主的树形结构的并发控制也有很好的效果)。
- LIPP相比于ALEX是一种时间换空间的策略。