计算机系统设计实验
前言
本篇文章记录了我的一门研究生课程,计算机系统设计的实验过程。
实验一:GEM5+NVMain模拟器
通过查阅官方文档,了解到目前gem5仅在Ubuntu18.04和Ubuntu20.04上通过了全部测试,这里我们选择在wsl-ubuntu20.04上进行试验。
首先安装需要的依赖:
1 | sudo apt install build-essential git m4 scons zlib1g zlib1g-dev \ |
gem5使用scons工具进行编译
1 | # scons build/{ISA}/gem5.{variant} -j {cpus} 这里ISA代表了指令集名称,variant代表的编译选项(debug,opt,fast三种选项),j后面代表的是编译的线程数。 |
编译完成后,gem5可以通过下述方式进行运行:
1 | ./build/{ISA}/gem5.{variant} [gem5 options] {simulation script} [script options] |
如何在gem5中运行一个脚本文件:在完成了上述的编译过程后,通过./build/X86/gem5.opt可以运行一个测试模式的脚本,具体的内容包括创建一个含有数据总线,cpu等结构的计算机系统。样例测试脚本在configs/example目录文件夹下。
实验一首先要求我们运行SE模式下的测试,直接在configs/example文件夹下找到需要的se.py文件,进行测试,后面使用编译好的静态文件hello作为测试参数:
1 | ./build/X86/gem5.opt configs/example/se.py -c tests/test-progs/hello/bin/x86/linux/hello |
得到的测试结果如下图: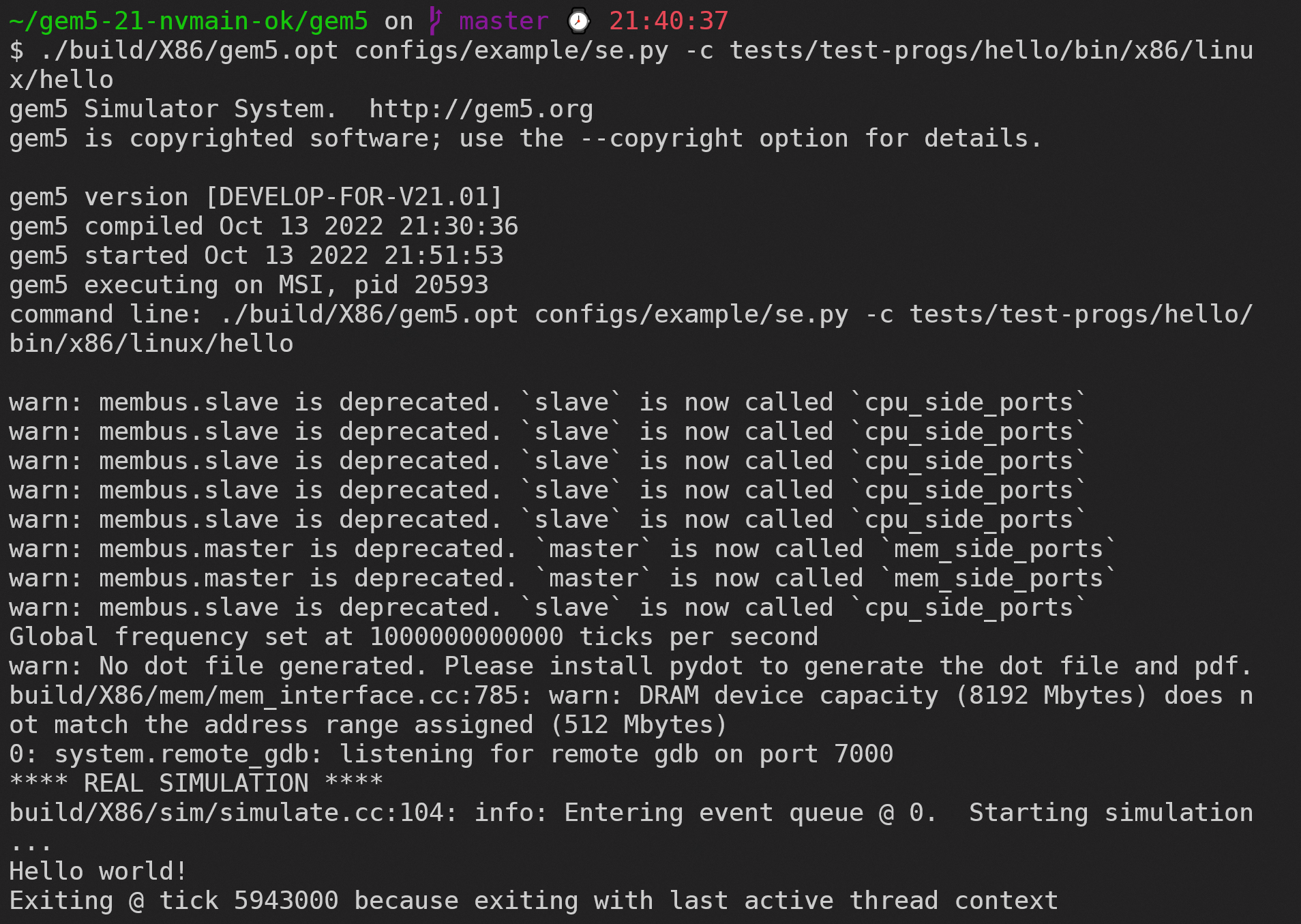
接下来进行全系统测试:
- 下载X86架构对应的全系统文件,也就是disk。
1
2
3mkdir full_system_images && cd full_system_images
wget http://www.m5sim.org/dist/current/x86/x86-system.tar.bz2
tar zxf x86-system.tar.bz2 && mv x86-system fs-image - 下载alpha对应的全系统文件,这是因为后面会用到里面解压出来的一个文件。这几步直接卡住了,提示404。。。
1
2wget http://www.m5sim.org/dist/current/m5_system_2.0b3.tar.bz2
tar zjf m5_system_2.0b3.tar.bz2
换个实验环境
最后我们的实验助教师姐给我们提供了往年学长打包好的docker,需要的可以在这里进行下载。为了在本地机器上配合wsl使用docker,首先需要我们升级wsl内核到wsl2,然后使用如下命令安装:
1 | wsl --install -d Ubuntu-18.04 |
在wsl2中使用docker可以参考这个博客,安装完成后拉取需要的docker镜像资源并运行:
1 | docker pull airmisuzu/gem-nvmain-parsec |
完成后就进入了docker目录下: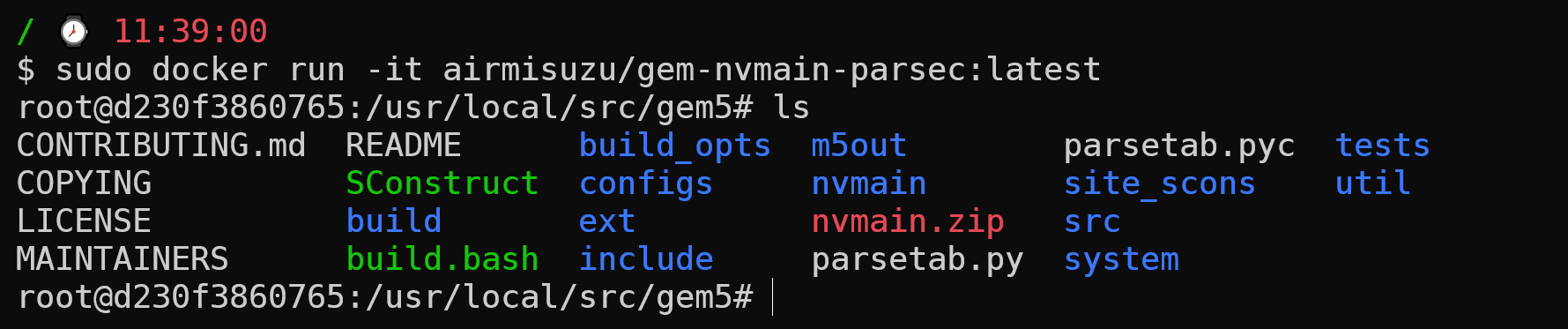
运行SE和FS测试
接下来重新进行实验一的内容,运行se模式测试:
1 | ./build/X86/gem5.opt configs/example/se.py -c tests/test-progs/hello/bin/x86/linux/hello |
实验结果截图: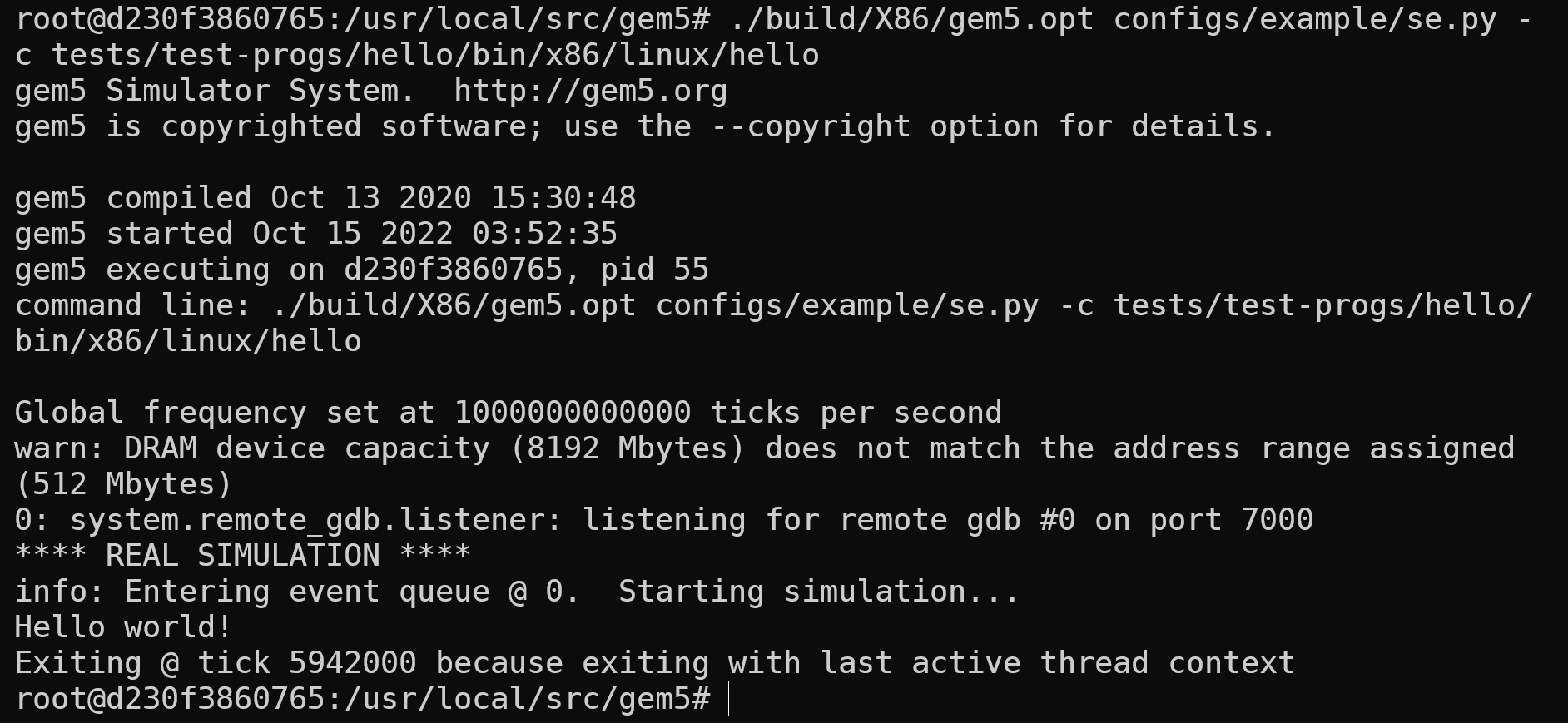
接下来进行fs全系统测试,首先检查磁盘镜像是否安装:可以看到src目录下有一个full_system_images文件夹用来保存磁盘和系统镜像。
1 | ./build/X86/gem5.opt ./configs/example/fs.py |
运行结果截图如下: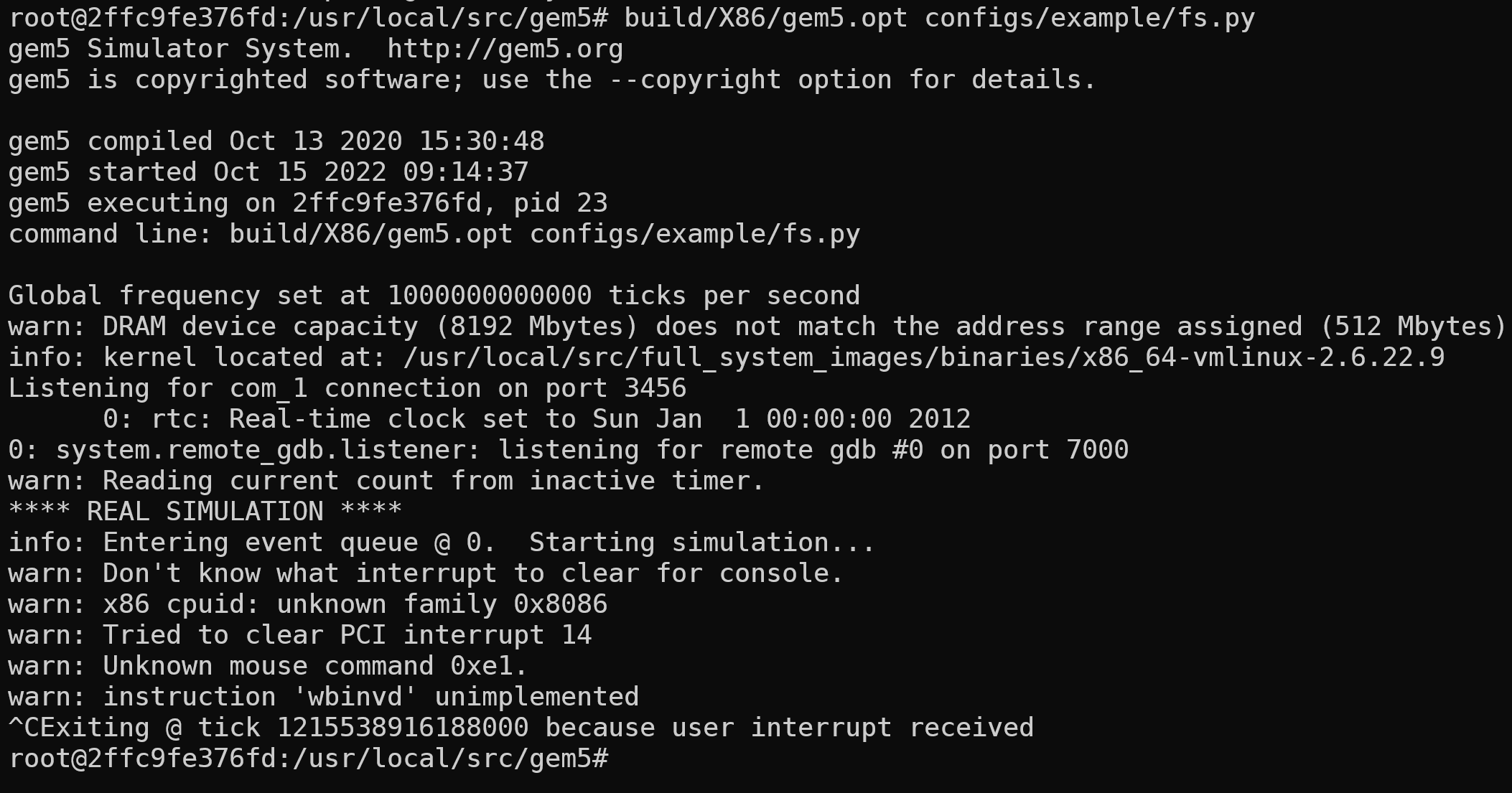
此时再开一个终端并进入同一个docker后在util/term目录下使用
1 | ./m5term 127.0.0.1 3456 |
连接到全系统模拟页面: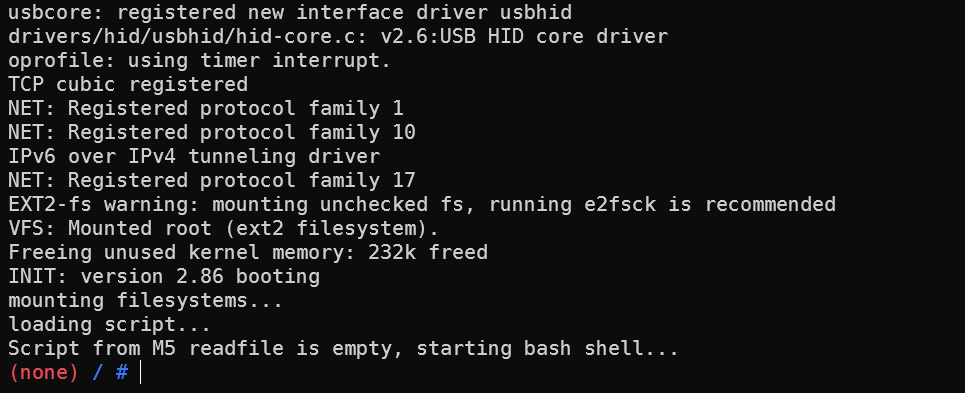
搭建GEM和NVMain混合编译环境并进行测试
接下来进行nvmain和gem混合编译并运行测试
1 | scons EXTRAS=nvmain ./build/X86/gem5.opt |
得到的实验结果截图如下: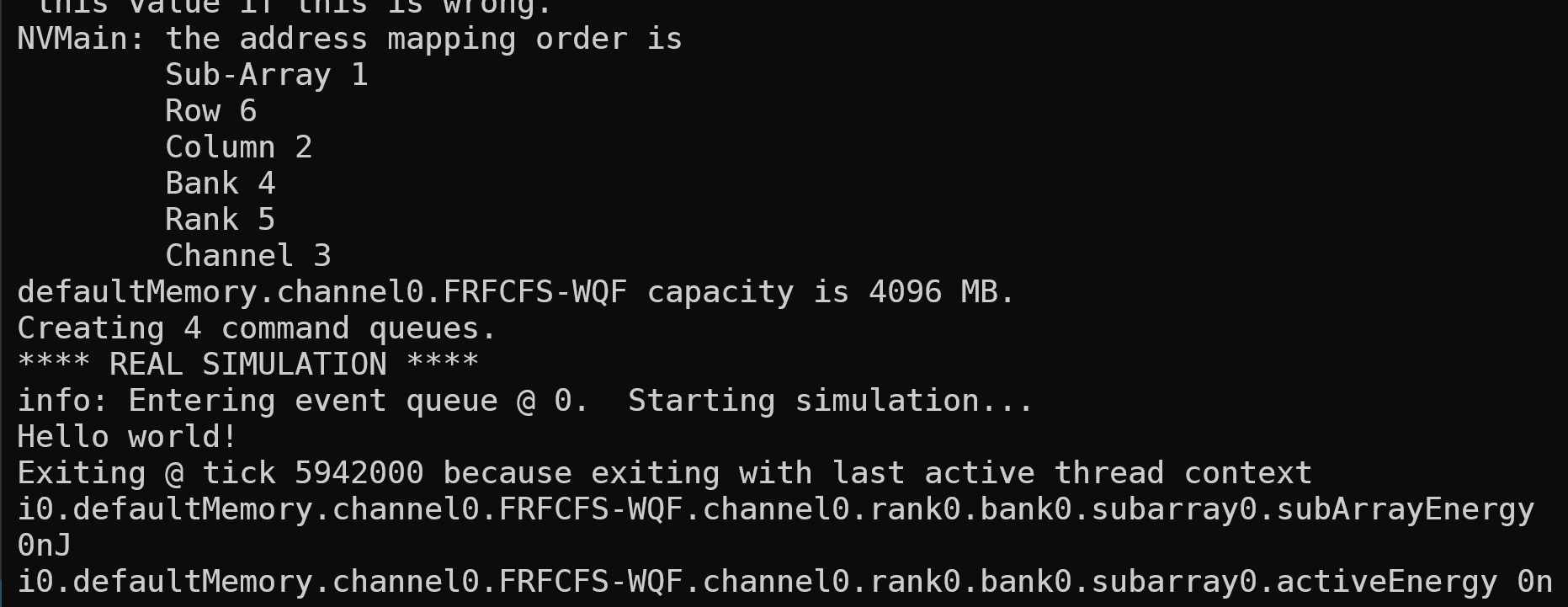
运行PARSEC 2.1负载
由于之前docker中已经下载好了需要的镜像文件,这里我们首先通过一个脚本设置测试参数:
1 | ../benchmark/TR-09-32-parsec-2.1-alpha-files/writescripts.pl blackschole 4 |
打开一个新终端使用telnet工具进行连接,得到的测试结果截图如下: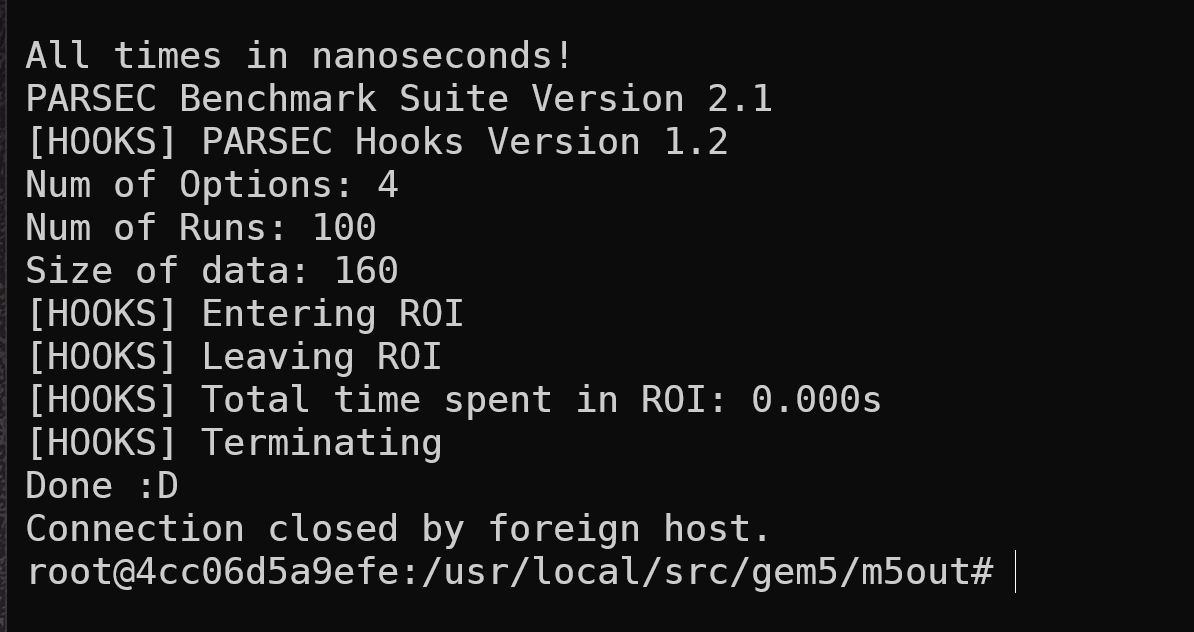
注意这里有个小坑,使用的linux内核镜像一定要使用2.6.22.9,其余的版本会有报错,目前还没有找到具体原因。
单独使用nvmain
接下来使用nvmain单独完成编译
1 | # 进入nvmain目录 |
得到的实验结果截图如下: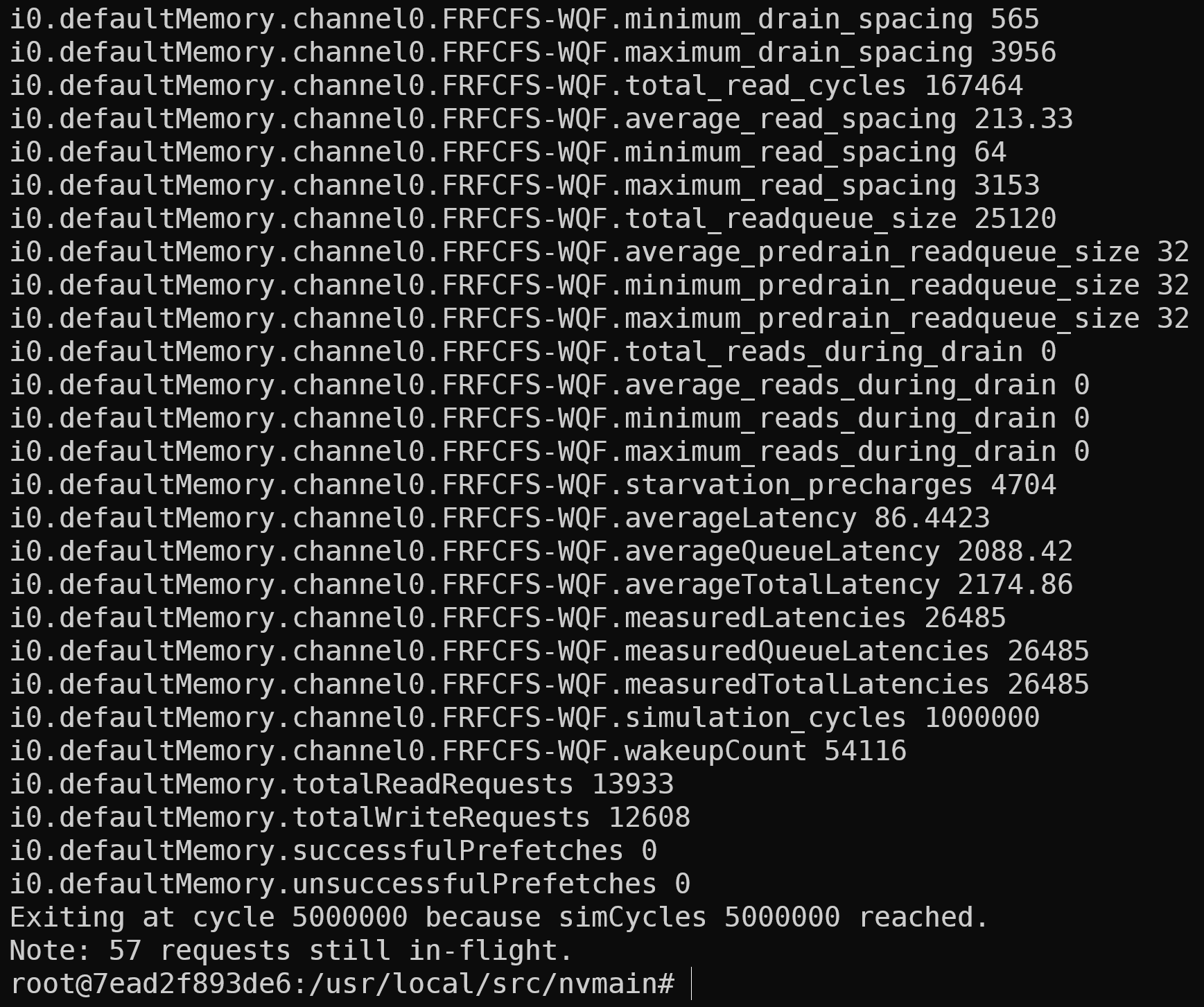
接下来实验要求我们统计数据写入类型。首先查看DataEncoderFactory.cpp文件,知道了默认的DataEncoder是没有的,为了实现FPC算法,我们可以参考FlipNWrite编码器的实现。最终实验要求我们阅读FPC算法,并最终实现nvm内部的数据压缩。
首先在DataEncoder目录下创建FPC目录,把FlipNWrite目录下的文件都拷贝过来,接着修改FPC.h文件,添加新的私有变量:
1 | private: |
接着修改FPC.cpp文件,首先观察需要实现的函数:
1. SetConfig函数:创建结构体并设置参数
2. Read函数:目前还不需要我们实现
3. Write函数:完成数据的压缩
4. RegisterStats函数:统计信息
5. Calculate函数:计算信息
明确了每个函数的用途后,首先我们了解FPC算法的原理。FPC算法的初衷是,由于一些小数据原本只需要占用较小空间,但是由于在操作系统中都用32位或者64字节进行存储,产生了资源浪费,为了在l2缓存上提升空间利用率,使用数据压缩算法,通过把8种数据压缩的情况使用三位bit进行编码,最终完成数据的压缩,论文中没有给出具体的样例,这里在网上找到了一个更好的样例表作为参考: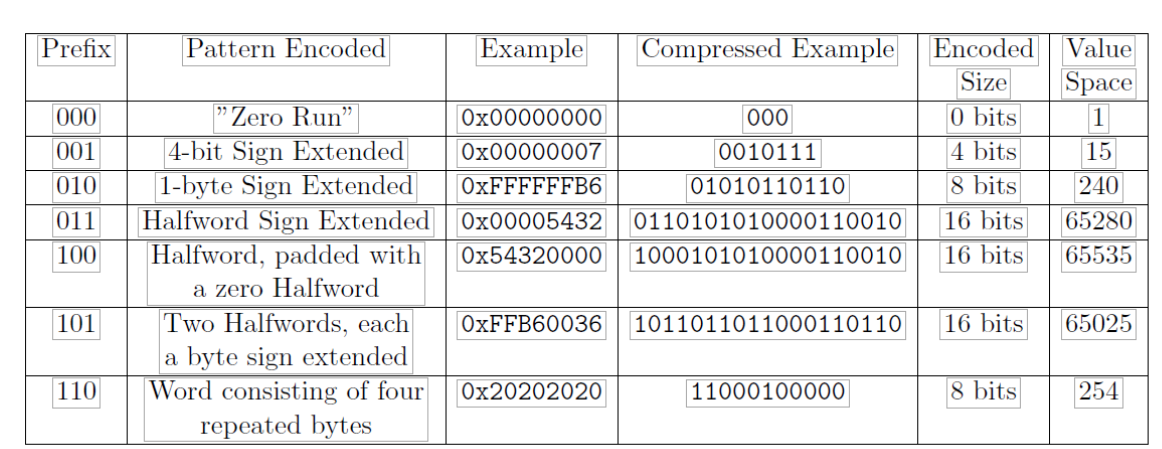
有了以上的压缩算法简介,接下来只需要我们把八种情况的条件判断实现即可,实现的目录结构见下图: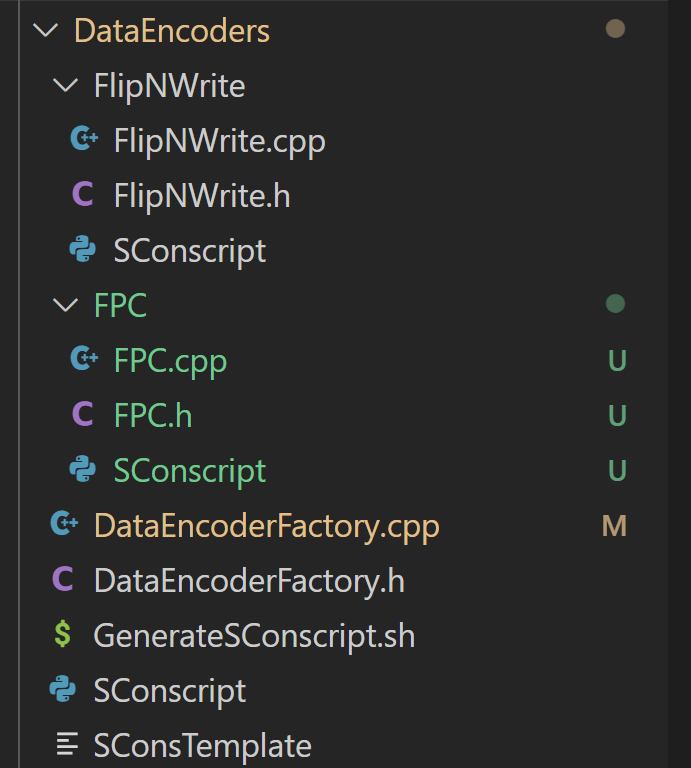
1 | // FPC.h |
1 | // FPC.cpp |
在完成上述文件编写后,还需要在DataEncoderFactory.cpp文件中添加FPC选项并把FPC头文件添加进去:
1 | DataEncoder *DataEncoderFactory::CreateDataEncoder( std::string encoderName ) |
在负载文件中的最后一行添加“DataEncoder FPC”,重新编译nvmain,并重新执行负载:
1 | scons --build-type=fast |
得到的测试结果截图如下: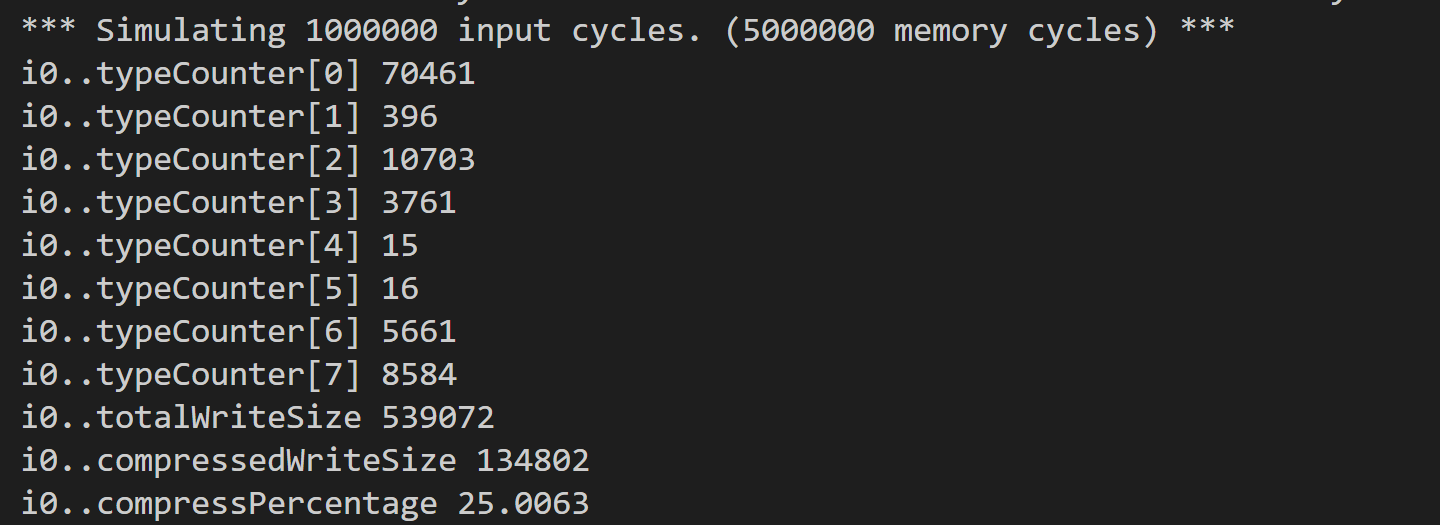
为了进一步进行对比,可以使用多个负载进行对比,这里就不进行赘述了。
实验二:编译安装quartz并实现哈希索引
编译安装quartz:
1 | git clone https://github.com/HewlettPackard/quartz.git |
实验要求中需要我们实现一个基于线性探测的hashmap,并且通过quartz提供的nvm仿真延迟静态库来模拟nvm中hashmap的延迟。
先实现一个简单的hashmap,之后在实验要求中介绍了:MFENCE和CLFLUSH指令后植入延迟的实现代码可参照:./quartz-master/src/lib/路径下的pflush.c文件。
quartz环境搭建
这个实验最难的部分在环境搭建过程,首先介绍quartz的编译过程中可能遇到的问题:
- cmake版本问题,这个就自己升级到cmake3以上的对应版本即可。
- 编译完成后在build/src/lib目录下会生成libnvmemul.so动态库,这个需要我们手动安装到/usr/local/lib目录下(当然也有其他的办法链接该库,使用cmake工具设置即可)
- 一定要找到满足quartz要求的cpu型号,否则可能会报错服务不存在。这里我使用的是实验室的服务器,cpu型号是:Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz
- 启用服务
1
sudo scripts/setupdev.sh load
实验流程
索引实现
实验首先需要我们实现一个基于线性探测的哈希索引,大家可以自行实现或者去github上找到一个开源的仓库fork。
重要:建议使用C进行实现,否则在后续的混合编译过程中会遇到许多问题
实现好哈希索引后,可以编写一个测试文件测试索引的功能和性能。修改代码
实验要求我们使用quartz提供的pflush和pmalloc完成内存的分配和管理,使用pflush和mfence来保证数据写入到NVM中。我们使用cmake工具管理我们的工程项目:1
2
3
4
5
6
7
8
9
10
11
12cmake_minimum_required(VERSION 3.20)
project(hashmap_quartz C)
set(CMAKE_C_STANDARD 99)
include_directories(include)
add_executable(hashmap_quartz main.c)
target_link_libraries(hashmap_quartz -lnvmemul)
target_link_libraries(hashmap_quartz -lm)我们之前已经把编译好的libnvmemul.so动态库复制到了/usr/local/lib中,这里我们直接通过-lnvmemul进行连接。
我的索引实现在include/hashmap.h文件中,首先在文件头部添加我们需要使用的api接口:1
2
3
4
5
6
7
8
9
void *pmalloc(size_t size);
void pfree(void *start, size_t size);
void pflush(uint64_t *addr);对于我们之前使用的malloc函数,直接使用pmalloc函数进行替换,pfree函数同理,这里给出一个例子:
1
2
3
4
5
6
7
8
9
10//pmalloc example
if (WITH_QUARTZ)
new->table = pmalloc(new->capacity * sizeof(struct DictEntry *));
else
new->table = malloc(new->capacity * sizeof(struct DictEntry *));
//pflush example
if(WITH_QUARTZ)
pfree(new, sizeof(HashMap));
else
free(new);针对数据写入操作,我们需要使用cflush函数来保证数据一致性,但是pflush函数只能一次写入uint64_t大小的数据,因此需要我们额外实现一个函数来满足大于8byte的数据写入操作。
1
2
3
4
5
6
7//tools
void pflush_n(void *addr, size_t size)
{
uint64_t *ptr;
for (ptr = addr; ptr < (uint64_t*)(addr + size); ++ptr)
pflush(ptr);
}这个函数通过把pflush额外进行一次封装,每次把写入数据拆分成多个8byte的数据进行操作,最终实现大数据的写入操作。之后把所有的需要进行数据写入操作的位置都使用pflush,pflush_n,asm_mfence等函数完成一致性保证。最终完成的实验代码可以见我的仓库。
最后使用quartz提供的脚本进行测试
1 | ./scripts/runenv.sh ../hashmap-quartz/build/hashmap_quartz |
得到的测试结果截图如下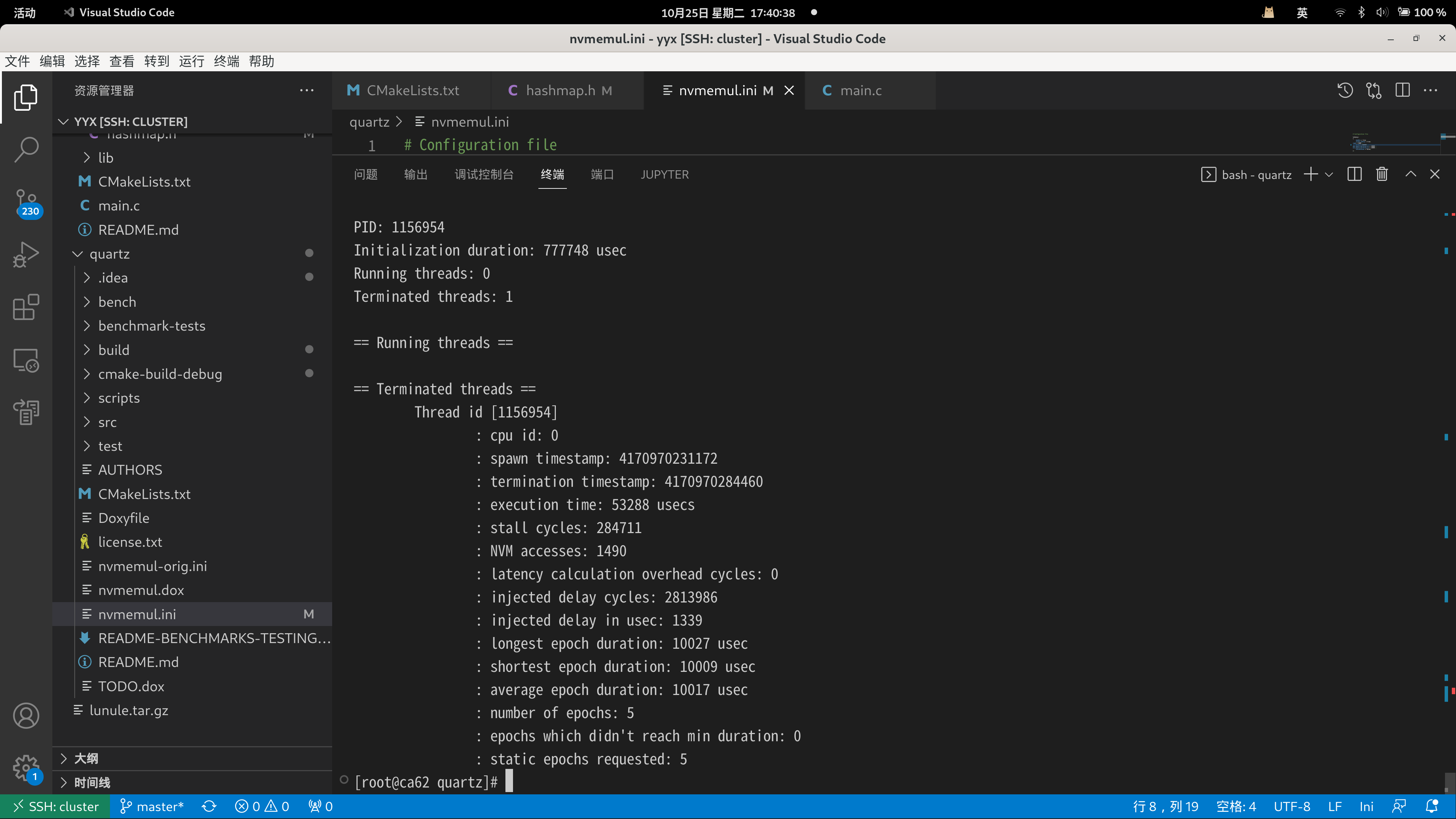
编写的测试插入了10000个键值对,对5000个键值对执行删除操作,最后查询10000个键值对。修改nvmemul.ini文件中的参数使用不同的写延迟参数进行测试,对比测试结果如下:
| 写操作延迟 | excution time | stall cycles | NVM accesses |
|---|---|---|---|
| 100 | 257832 | 14476876 | 75795 |
| 1000 | 299927 | 13452847 | 70433 |
| 10000 | 751748 | 13951981 | 73047 |
| 100000 | 5251249 | 15238005 | 80624 |
| 1000000 | 50234309 | 23134933 | 121125 |
开始准备使用测试出来的执行时间参数作为写入时间的参考标准,后面发现这样测试并不准确,于是决定调用sys/time.h库中的计时函数完成对hashmap
插入操作的执行时间测量。最终的代码已更新到仓库中。
实验参考
[1] 知乎专栏:gem5模拟器入门
[2] csdn博客:GEM5的全系统模拟
[3] Xiaoguang Zhu’s Blog gem5、NVMain、Quartz 实验笔记
[4] 使用gem5运行PARSEC基准测试