FINEdex文献阅读
研究现状
随着现有数据量的快速增长,人们考虑使用学习索引来替换传统的索引结构。但是传统的学习索引无法解决高并发需求,作者首先总结了现有的学习索引存在的短板:
- 有限的可扩展性。针对插入更新操作,现有的学习索引很难拥有很好的性能。目前提出的一些学习索引结构只能单独的解决高并发的读,写,重训练。FITing-tree,ALEX,PGM-index都没有考虑数据一致性问题。XIndex通过把数据保存在不同的数据结构中来解决并发的数据一致性问题,这样会导致范围查询操作的性能低下。
- 高开销问题。XIndex和FITing-tree都是通过建立一个delta buffer来解决插入操作,该缓冲区是B+树或者Mass树。并且XIndex显示,当缓冲区过大时,会产生很大程度的性能下降。ALEX和PGM-index是通过在索引结构中保留了空槽来解决插入时产生的高开销问题。一旦发生多线程访问时,会发生多个线程的冲突访问情况,这会导致并发操作的性能下降。
作者提出了FINEdex做出了如下贡献:
- 高可伸缩性。提出了一种用于并发内存系统的非粒度学习索引方案,即FINEdex,它有效地满足了可伸缩性的要求。主要的贡献是通过充实的数据结构来减少数据依赖性,并同时在两个粒度中对模型进行重新训练。
- 低开销的索引操作和无阻塞的重训练操作。
- 系统应用以及评测。
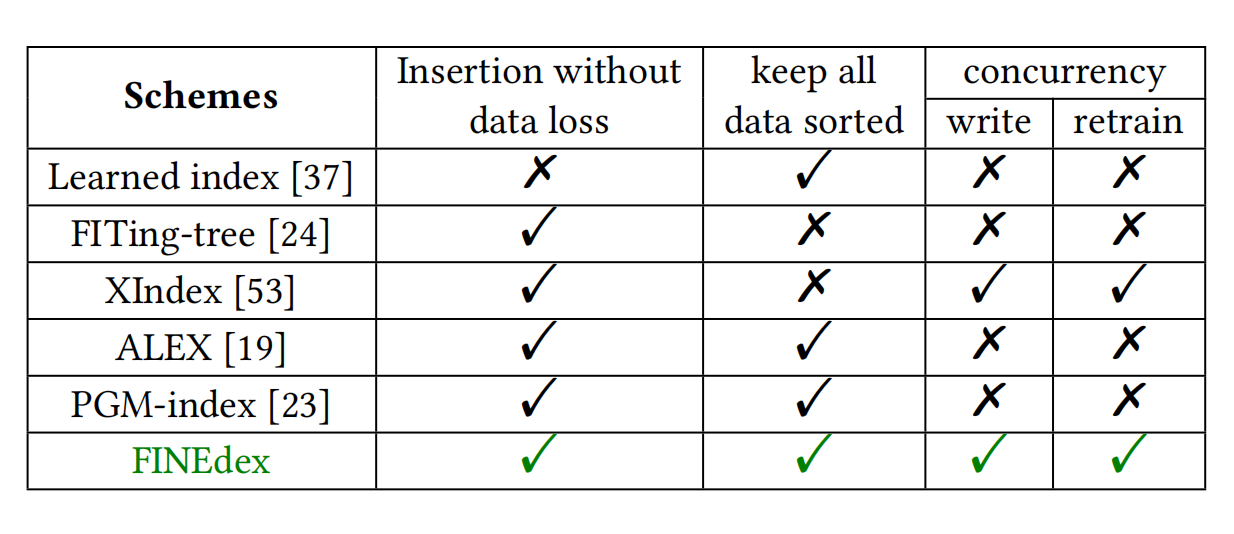
上图给出了目前现有的学习索引的功能。
设计部分介绍
首先给出了数据结构设计部分。
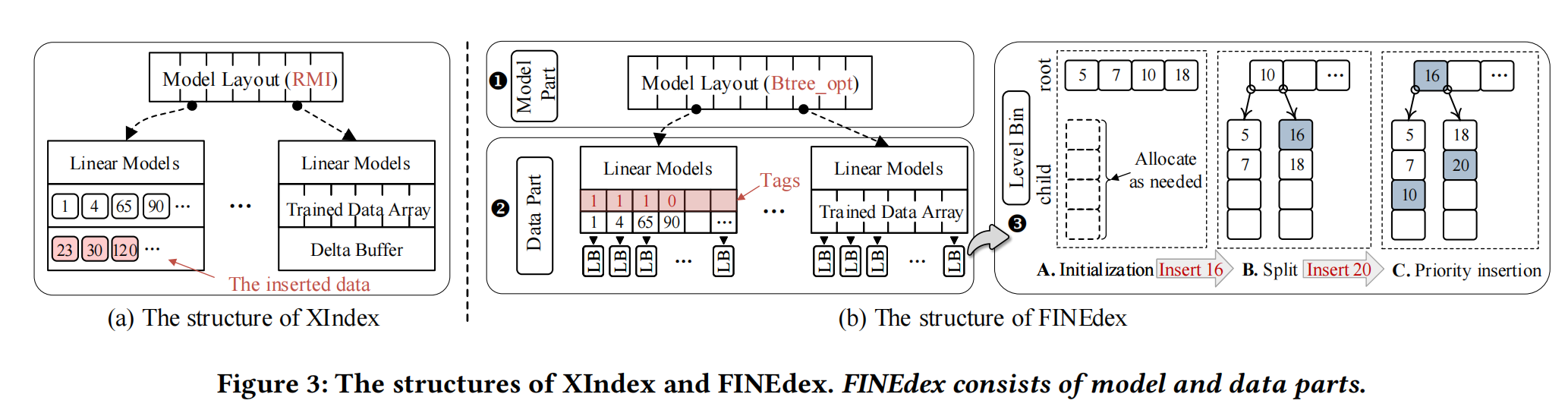
作者通过对XIndex的设计结构进行修改,实现了一个高效的并发性数据索引结构。实现了一个两级的有序数组结构。该结构能够很好的避免数据依赖性并且能够保持数据的有序性。并且在插入的过程中,旧数据的访问不会受到影响。只有当缓冲区满了的时候,才会发生数据合并以及模型重训练操作。作者把整个设计分成了两个部分:
- 模型部分:这些独立的模型可以通过并发的再训练来适应新的数据分布。
- 数据部分:通过层级结构,建立了两层有序数组,提供能快速重训练的方案。
- 模型部分,首先作者设计了一个方案来提高模型的准确率。学习探针算法LPA。通过在f(x)函数周围建立一个平行四边形囊括所有的训练数据,之后再使用线性回归模型进行拟合。传统的RMI模型,由于无法针对不同分布的数据来决定模型的个数,RMI模型的准确率一直是一个潜在的问题。LPA算法通过设置一个错误率阈值,来判断某一组数据是否为线性分布的。如果大于这个阈值,那么移除该数据集靠后的一部分数据,如果小于阈值,那么添加新的数据进入原来的数据集中再重新训练。这个过程一共需要提供如下几个参数:
- threshold:错误率阈值。
- learning_step:学习步长,用来决定学习速度的参数之一。
- learning_rate:学习率,用来决定学习速度的参数之一。
整个过程是一个贪心算法。最终得到的输出是一串错误率为threshold的线性模型链。
除了以上的几个参数设置,作者还提出了优化模型输出的方案。上面提到了LPA算法得到的是一串线性模型链,在执行查找等操作时,需要顺序遍历整个模型链。最终作者选择使用优化后的b树来存储这些模型<key,model>,key代表了一个模型的最大元素。
数据部分,主要解决了并发性问题。每一个模型都有一个小型的缓冲区来解决修改和插入等操作。整个小型缓冲区被设计成了两层的b树结构,在训练好的模型中,每个数组中的元素都有一个bin指针,用来指向level bin缓冲区,该缓冲区分为root层和child层,首先插入的数据会被放到root层,随着root层满了,会创建child节点来存储新插入的节点,之后插入的节点会优先插入到靠前的child节点来节约空间使用。缺陷:在插入的过程中需要不断地调整树形结构,这可能会造成很大的性能开销
紧接着,作者提出了在并发情况下的模型重训练设计思路。作者把重训练分成了两个部分:level-bin重训练和模型重训练。
- level-bin重训练
作者提出每当一个level-bin层满了之后,只需要对一个该层进行重训练,不需要影响其余的level-bin节点,产生的时间开销仅有27us - 模型重训练
作者通过使用RCU技术保证了新模型的训练过程中,旧模型的访问操作不被影响。由于level-bins是通过指针指向的,我们只需要在复制的过程中使用新的指针指向level-bin即可。模型重训练会在模型需要重新训练一个更小的模型时被触发。
- level-bin重训练
并发:作者通过提出一系列方案来解决并发冲突
- 写写冲突:当不同线程需要对同样的数据或者是bin进行修改会产生写写冲突。作者提出使用细粒度的锁分别对记录和bin进行上锁。对记录上锁的操作比较简单,对于bin上锁,需要根据情况进行上锁,有的时候可能只需要对child bin进行上锁,有的情况需要对root bin也进行上锁。
- 读写冲突:通过使用版本控制实现数据一致性。每次完成训练后,都会给模型和数据分配一个版本号。在一次访问过程中,首先会获取版本号,如果在读取完成后版本号没有发生改变,那么说明读取操作的数据是有效的,如果无效那么重新发起读请求。
测试部分介绍
在redis中进行测试。只修改了基础的排序数据结构。一共提供了六个常见的api(train,get,put,update,remove,scan)。一共分配了4个线程来执行模型的重训练,访问过程一共分为三步:在模型中进行查找,计算区间,操作level-bin。使用24线程进行测试。使用了Masstree,Xindex,LI+Δ三个索引设计方案进行对比。没有采用redis原生的跳表结构进行对比,因为其与树形结构的性能比较类似。使用LI+Δ方案时,为了让其支持并发操作,使用了XIndex的delta buffer方案,使用masstree管理该缓冲区。FIT树由于不支持并发没有进行比较。
- 配置部分:学习索引结构都使用了两层RMI模型,第二层最多容纳250k的模型数量(XIndex中得出的结论)。FINEdex的threshold我们设置成32,level-bin层的root设置成8,child bin大小设置为16。
- 使用的测试工具:
- YCSB测试工具:一共提供了六种不同的测试负载。
- 网络博客负载
- 文档id负载