- HDFS文件系统学习(元数据部分)
HDFS文件系统学习(元数据部分)
- 为了完成我的毕业设计,之前一直看的是cephfs系统。后面发现直接在源码上进行修改不是特别实际,决定自己搭建一个简单的小型文件系统进行修改。最后我选择了看上去比较简单的HDFS。
HDFS整体架构
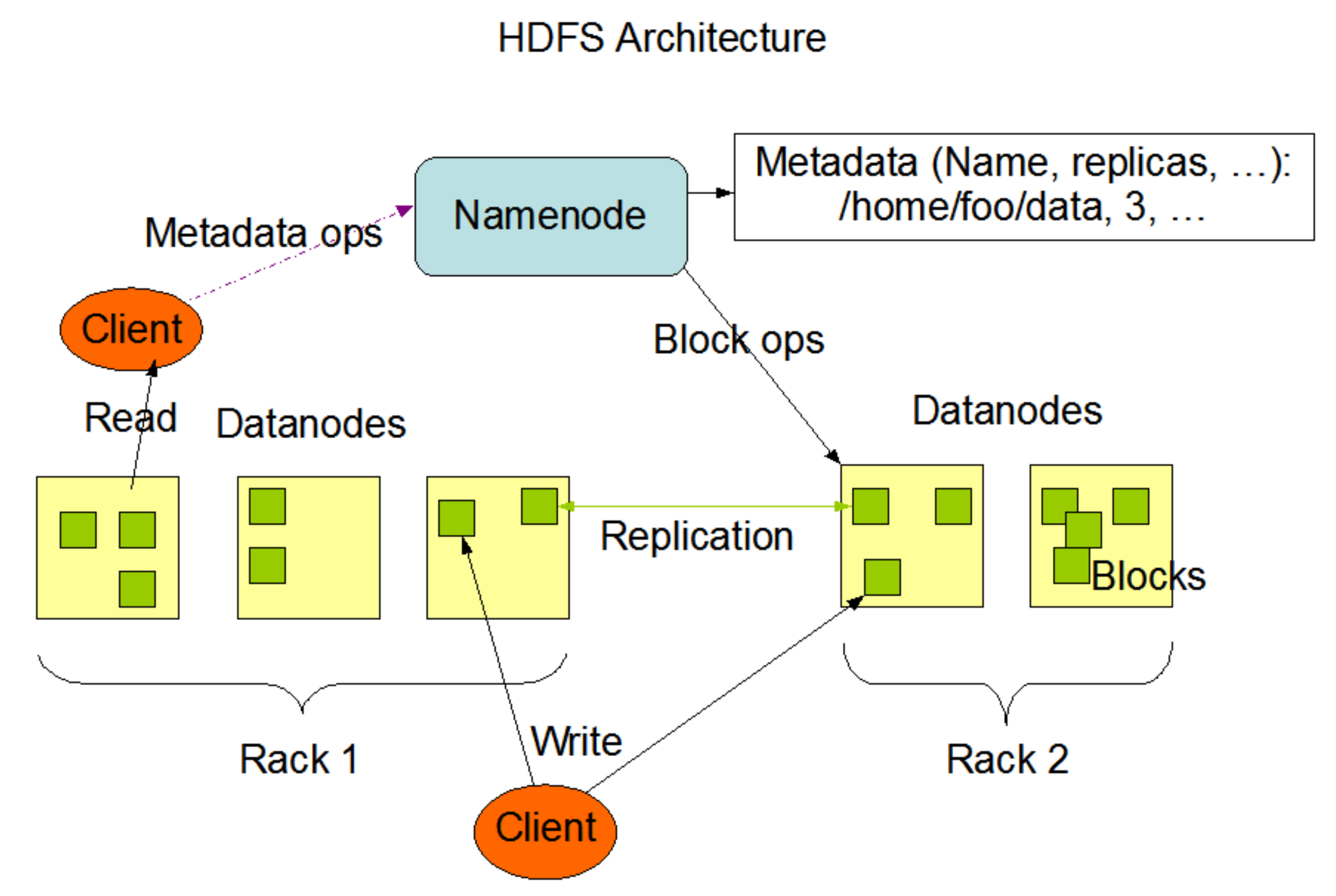
- 上面是HDFS的大致结构图,我的毕业设计是针对元数据部分的,于是我重点关注了HDFS的NameNode部分。
Namenode架构
简述
NameNode对于整个HDFS是最重要也是最容易出现问题的部分,一旦NameNode发生了故障就会导致整个系统停机。同时随着数据规模的增大也会发生性能瓶颈。
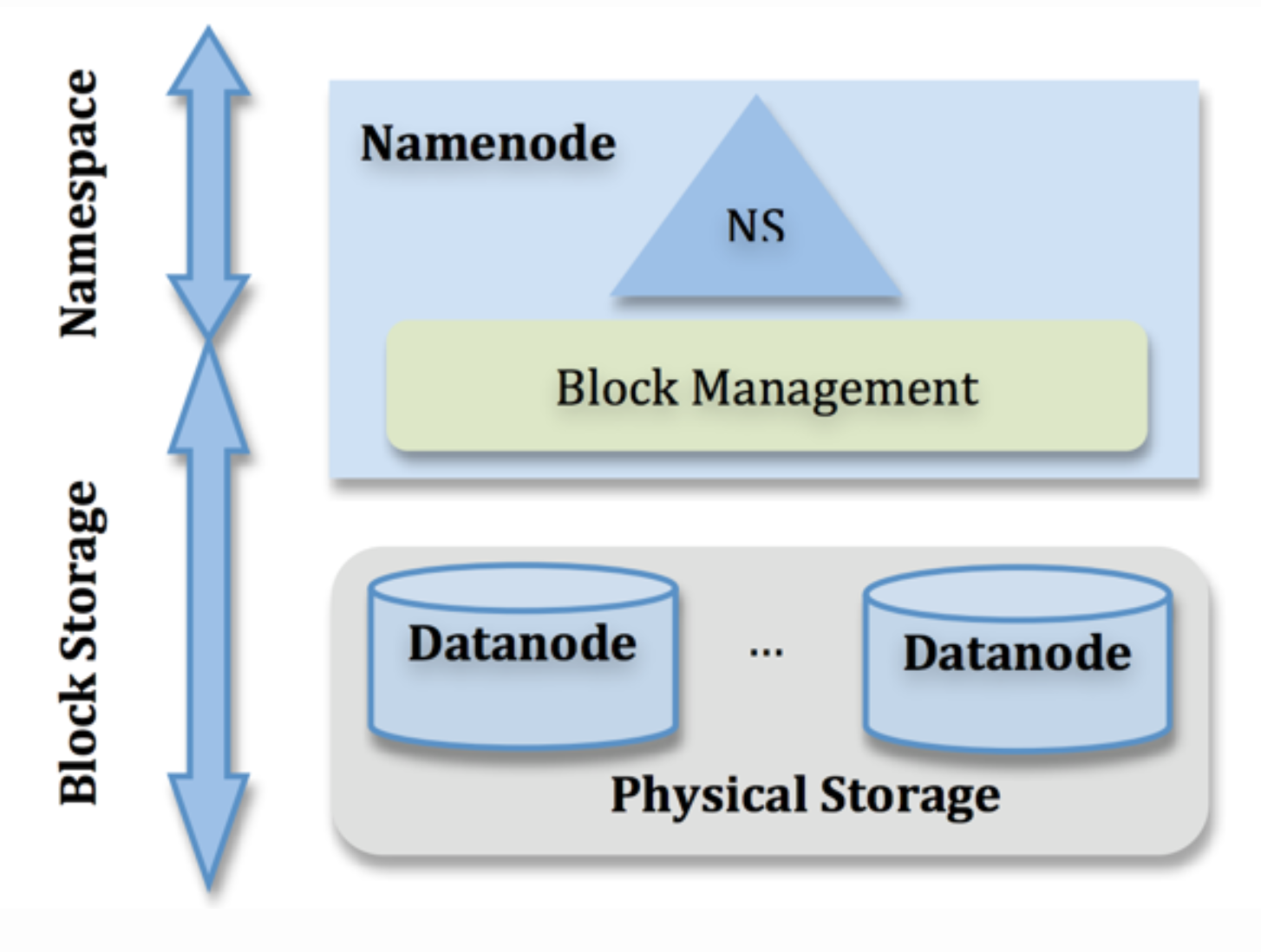
NameNode管理整个HDFS的文件系统元数据,对于NameNode,我们又可以细分成两个部分:
- Namespace管理层:这个部分主要是文件系统的目录树以及每个文件对应的元数据块映射。Namespace通过这个映射访问块映射管理层的数据来获取元数据。
- 块映射管理层:这个部分存储了每个文件的数据块与实际存储系统中物理块的位置的映射。
以上的两个管理层中的数据都是驻留在内存中的,为了防止系统宕机导致数据无法恢复,专门引入了FsImage和editlog技术。Namespce管理层会周期把文件系统存储到FsImage持久化设备中。并且,每一次Namespace中的操作也都会存入editlog持久化文件中。一旦发生重启,首先会从FsImage中恢复并且根据editlog把Namespace恢复到重启前的状态。之后根据每一个DataNode反馈的信息重新建立块管理层的映射。
NameNode全景
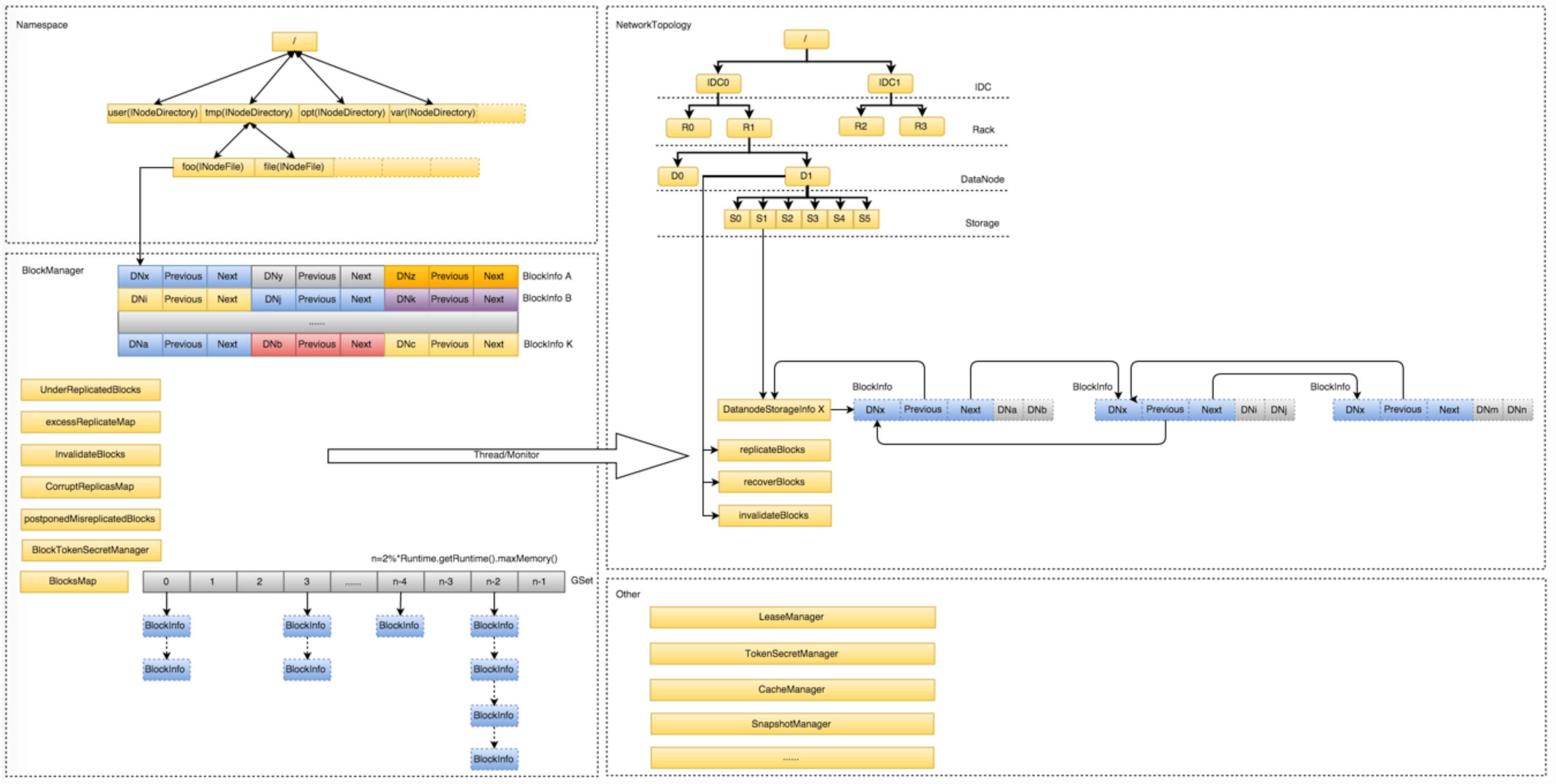
上图给出了NameNode的内部架构细节图,这里就不再赘述了。接下来主要针对系统中可能遇到的性能瓶颈进行分析。
Namespace多方面分析
和一般的单机文件系统比较类似,Namespace也是建立了一个文件目录树,其中包括了两种数据类型:INodeFile和InodeDirectory。InodeDirectory通过一个ArrayList存储所有的子目录或者文件。一旦文件系统的数据量变得十分巨大,会导致内存占用量变得很大以及对于对于Inode定位速度发生下降。
NameNode的垃圾回收机制是基于JVM的FGC的,一旦发生内存回收失败会导致空间被降级到串行内存回收,产生巨大的停顿。
NameNode的调试问题,一旦数据量较大,会导致内存占用巨大,甚至导致NameNode不可用。
有人提出了通过多个节点分别管理子目录树来实现NameNode的负载压力,这种方式已经被广泛使用。
ALLUXIO工程师提出使用Rocksdb来存储高性能的文件系统树,不过是在SSD上构建的,但是可以存储更多的元数据(HDFS一般情况下JVM允许的内存空间在64GB,远远不能达到十亿级别的元数据要求),并且为了弥补把元数据迁移到SSD上存储的损失,在内存中会建立缓存。
Gitalk 加载中 ...