- pmemkv组件学习
简介
- pmemkv是一个基于pmdk以及多个基础组件库,并且在持续性存储介质上实现kv存储的引擎。主要由c/c++实现,并且完成了和多个语言的绑定。具体结构图如下:
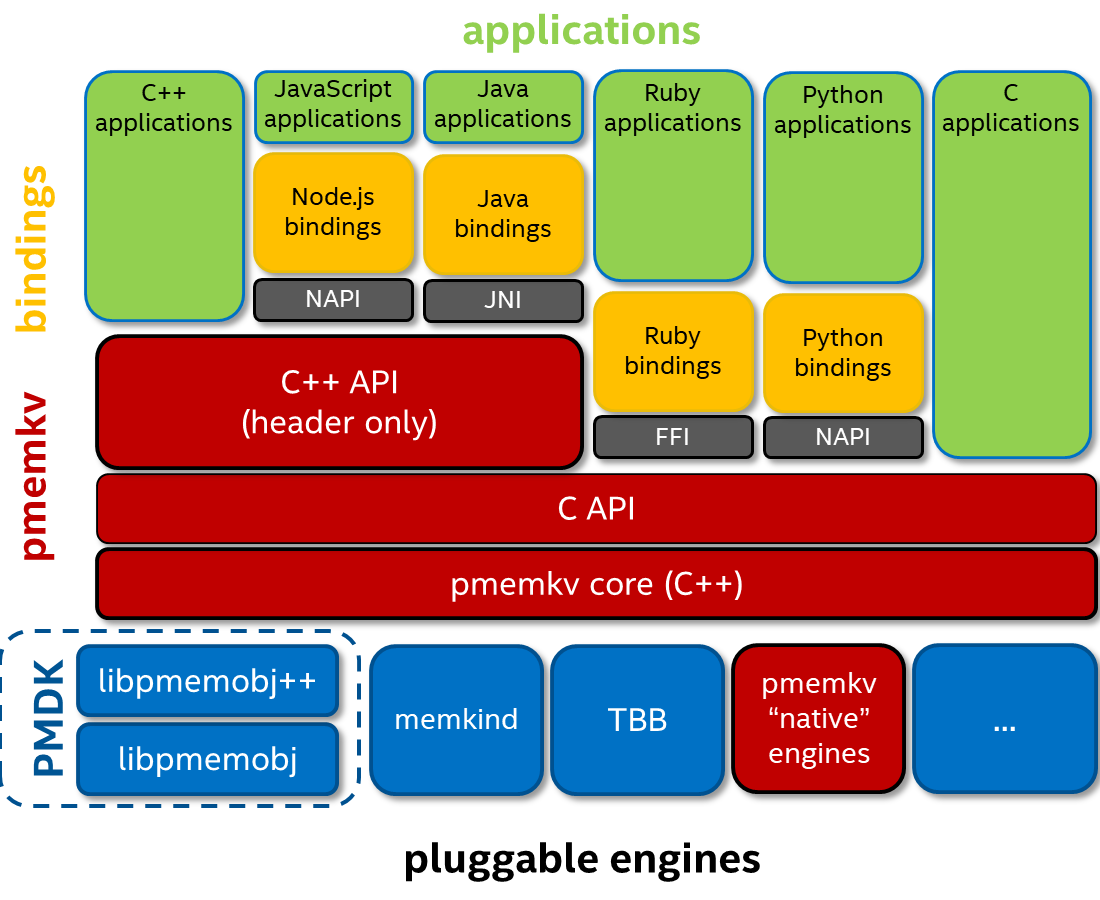
- pmemkv数据库中存储的键和值可以是任意的二进制数据,可以包含多个空字符。每一个接受key值得函数都需要一个指向const char类型得指针和大小size_t
简单的API介绍(C语言)
int pmemkv_open(const char *engine, pmemkv_config *config, pmemkv_db **db)- 打开一个pmemkv得数据库参数engine代表了选取的引擎名称,config代表已经在dram中创建好的config,代表打开一个config(意味着其他的pmemkv不能再次打开相同的config了),最后db参数指向的是创建好的指向数据库实例的指针。
void pmemkv_close(pmemkv_db *kv)- 关闭pmemkv数据库
int pmemkv_count_all(pmemkv_db *db, size_t *cnt)- 统计数据库中所有的记录数,保存在cnt中
int pmemkv_count_above(pmemkv_db *db, const char *k, size_t kb, size_t *cnt)- 存储键值长度比kb大的目录条数,返回值在cnt中(键值得大小比较在/src/comparator中定义)
int pmemkv_count_below(pmemkv_db *db, const char *k, size_t kb, size_t *cnt)- 存储键值长度比kb小的目录条数,返回值在cnt中
int pmemkv_count_between(pmemkv_db *db, const char *k1, size_t kb1, const char *k2, size_t kb2, size_t *cnt)- 存储键值在k1和k2之间的所有目录条数,返回值在cnt中
int pmemkv_get_all(pmemkv_db *db, pmemkv_get_kv_callback *c, void *arg)- 针对存储在数据库中的每一条目录都执行函数c,对于函数c(类似于c++中的iterator)会传入以下参数:
- 指向键值的一个指针
- 该键值的长度
- 指向对应的value的指针
- 对应value的长度
- 以及需要用户指定的一系列参数
- 函数c可以通过返回非0值来停止迭代(可以修改函数c的返回值来进行中断)这种情况下pmemkv_get_all会返回一个PMEMKV_STATUS_STOPPED_BY_CB,如果迭代过程中c函数一直返回值为0就不会发生中断。
- 针对存储在数据库中的每一条目录都执行函数c,对于函数c(类似于c++中的iterator)会传入以下参数:
int pmemkv_get_above(pmemkv_db *db, const char *k, size_t kb, pmemkv_get_kv_callback *c, void *arg)- 这个函数相比pmemkv_get_all就仅仅是添加了一个键值以及其长度,只遍历比这个键值大的条目
int pmemkv_get_below(pmemkv_db *db, const char *k, size_t kb, pmemkv_get_kv_callback *c, void *arg)- 这个函数同理,不赘述
int pmemkv_get_between(pmemkv_db *db, const char *k1, size_t kb1, const char *k2, size_t kb2, pmemkv_get_kv_callback *c, void *arg)- 同理不赘述
int pmemkv_exists(pmemkv_db *db, const char *k, size_t kb)- 用来检查db中是否存在键值为k,长度为kb的条目,成功返回PMEMKV_STATUS_OK,不成功返回PMEMKV_STATUS_NOT_FOUND,其余的可能返回值会在ERROR中说明
int pmemkv_get(pmemkv_db *db, const char *k, size_t kb, pmemkv_get_v_callback *c, void *arg)- 在db上查找键值为k(长度为kb)的条目调用的是函数c,返回的arg指向了value实际存储的位置(这个函数感觉和exist比较类似,唯一的区别是这里可以调用c和参数arg),这里的函数c需要我们重新定义
int pmemkv_get_copy(pmemkv_db *db, const char *k, size_t kb, char *buffer, size_t buffer_size, size_t *value_size)- 相比于上面的get,这里需要我们多传入一个缓冲区用来接收复制得到的value数据,缓冲区大小以及用来存储返回value长度的value_size变量
int pmemkv_put(pmemkv_db *db, const char *k, size_t kb, const char *v, size_t vb)- 把键值对插入到pmemkv数据库中当这个函数之后,缓冲区可以被重新复用
int pmemkv_remove(pmemkv_db *db, const char *k, size_t kb)- 删除某个键值
int pmemkv_defrag(pmemkv_db *db, double start_percent, double amount_percent)- 从start_percent开始,对amount_percent百分比的元素进行碎片整理
pmemkv-benchmark
针对pmemkv,专门推出了一个pmemkv-benchemark的仓库,专门用来进行性能评测,接下来我准备利用这个库进行性能评测
pmemkv-bench简介
- 这个是基于leveldb和rocksdb的db_bench程序(都在两个数据库的开源项目中的benchmark文件夹中),支持的参数列表会有不同,注意在每次测试的之后需要删除数据库,不然在下一次测试的时候会发生把数据写入到现存的数据库中。
测试
- 首先我决定先了解测试参数的含义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25--engine=<name> (选择使用的引擎,默认是cmap)
--db=<location> (选择创建的数据库的路径,默认的是/dev/shm/pmemkv_test_db)
(注意,一定要在DAX文件系统中,DAX设备或者是poolset的文件)
--db_size_in_gb=<integer> (创建的数据库池的大小,以GB为单位,默认值为0)
(如果是已经存在的poolset或者是已经存在的DAX设备,直接设置为0或者使用默认值)
(如果db的路径没有poolset,这个值必须设置为大于0的数)
--histogram=<0|1> (在报告延迟时显示直方图)
--num=<integer> (需要放入数据库的键值数量,默认值为1000000)
--reads=<integer> (读操作的数量,默认值为1000000)
--threads=<integer> (同时创建的线程数,默认值为1)
--key_size=<integer> (键值的大小,以byte为单位,默认值为8)
--value_size=<integer> (value的大小,以byte为单位,默认值为100)
--readwritepercent=<integer> (读写操作的比例,90代表着读写操作总数的90%是读操作,意味着9个get函数就会有1个put函数)
--tx_size=<interger> (每个线程的一个事务插入的条目数,默认是10)
--disjoint=<0|1> (指定每个线程是否处理不相交的键集合,默认是0)
--benchmarks=<name>, (选择只进行某个部分的测试)
fillseq (load N values in sequential key order)
fillrandom (load N values in random key order)
readseq (read N values in sequential key order)
readrandom (read N values in random key order)
readmissing (read N missing values in random key order)
deleteseq (delete N values in sequential key order)
deleterandom (delete N values in random key order)
readwhilewriting (1 writer, N threads doing random reads)
readrandomwriterandom (N threads doing random-read, random-write) - 克隆项目:
git clone https://github.com/pmem/pmemkv-bench.git - 根据readme确认以来是否都已安装,设置libpmemkv.so.1的路径(使用
sudo find -name libpmemkv.so.1查找所在位置,如果已经make install了pmemkv可以直接在默认路径下找到)
export LD_LIBRARY_PATH=/usr/local/lib/ make bench进行编译- 这里我直接在DRAM上进行测试
PMEM_IS_PMEM_FORCE=1 ./pmemkv_bench --db=/dev/shm/pmemkv --db_size_in_gb=1最后会发现在终端上输出了测试结果,这里稍作修改,把测试结果输出保存到csv文件中方便进行以后的数据分析。
- 首先我决定先了解测试参数的含义
测试结果分析
- 由于我们没有持续性存储介质,我们所有的操作都是在dram中完成的,在参阅了参考文献后,我们发现读操作DRAM和PM的性能更加相近,于是我们决定首先分析读取的性能情况,这里我们选取的是最稳定的引擎cmap,之后也会进行多个引擎的横向性能对比。
- 我选取的参数变量表:
变量名称 参数选择1 参数选择2 参数选择3 参数选择4 参数选择5 参数选择6 参数选择7 参数选择8 参数选择9 dbsize 1 2 3 - - - - - - keynum 100 1000 10000 100000 1000000 - - - - threads 1 2 4 8 - - - - - reads 100 1000 10000 100000 1000000 - - - - keysize 1 2 4 8 16 - - - - valuesize 1 2 4 8 16 32 64 128 - readwritepercent 10 20 30 40 50 60 70 80 90 txsize 1 2 4 8 16 - - - - disjoint 0 1 - - - - - - - - 我们直接获取数据并完成作图:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.ticker as ticker
dram_dbsize=pd.read_csv("./result/dram_dbsize.csv")
dram_keynum=pd.read_csv("./result/dram_keynum.csv")
dram_threads=pd.read_csv("./result/dram_threads.csv")
dram_reads=pd.read_csv("./result/dram_reads.csv")
dram_keysize=pd.read_csv("./result/dram_keysize.csv")
dram_valuesize=pd.read_csv("./result/dram_valuesize.csv")
dram_readwritepercent=pd.read_csv("./result/dram_readwritepercent.csv")
dram_txsize=pd.read_csv("./result/dram_txsize.csv")
dram_disjoint=pd.read_csv("./result/dram_disjoint.csv")
optane_dbsize=pd.read_csv("./result/optane_dbsize.csv")
optane_keynum=pd.read_csv("./result/optane_keynum.csv")
optane_threads=pd.read_csv("./result/optane_threads.csv")
optane_reads=pd.read_csv("./result/optane_reads.csv")
optane_keysize=pd.read_csv("./result/optane_keysize.csv")
optane_valuesize=pd.read_csv("./result/optane_valuesize.csv")
optane_readwritepercent=pd.read_csv("./result/optane_readwritepercent.csv")
optane_txsize=pd.read_csv("./result/optane_txsize.csv")
optane_disjoint=pd.read_csv("./result/optane_disjoint.csv")
item_list=["fillseq","fillrandom","readseq","readrandom","readmissing","deleteseq","deleterandom","readwhilewriting","readrandomwriterandom"]
def show_plots(dataset0,dataset1,x,x_label,x1_label,y_label,rowname):
#dbsize
tempy0=[]
tempy1=[]
for i in dataset0[dataset0["Benchmark"]==rowname][y_label]:
tempy0.append(float(i))
for i in dataset1[dataset1["Benchmark"]==rowname][y_label]:
tempy1.append(float(i))
#设置ylim
y_lim=max(tempy0)
if max(tempy0)<max(tempy1):
y_lim=max(tempy1)
fig,ax=plt.subplots(figsize=(6.4,4.8), dpi=100)
#画图
ax.plot(x,tempy0, label=x_label, linestyle='-', marker='*', markersize='10')
ax.plot(x,tempy1, label=x1_label, linestyle='-', marker='*', markersize='10')
#设置坐标轴
ax.set_ylim(0,y_lim*1.3)
ax.set_xlabel(x_label, fontsize=13)
ax.set_ylabel(y_label, fontsize=13)
#设置刻度
ax.tick_params(axis='both', labelsize=11)
#显示网格
#ax.grid(True, linestyle='-.')
ax.yaxis.grid(True, linestyle='-.')
#添加图例
legend = ax.legend(loc='best')
plt.title(rowname)
plt.gca().xaxis.set_major_formatter(ticker.FormatStrFormatter('%1.1f'))
if(y_label=="micros/op (avarage)"):
plt.savefig("./images/"+rowname+"/latency/"+x_label+"_"+x1_label+".png")
else:
plt.savefig("./images/"+rowname+"/bindwidth/"+x_label+"_"+x1_label+".png")
plt.show()
for item in item_list:
show_plots(dram_dbsize,optane_dbsize,[1,2,3],"dram_dbsize","optane_dbsize","micros/op (avarage)",item)
show_plots(dram_keynum,optane_keynum,[100,1000,10000,100000,1000000],"dram_keynum","optane_keynum","micros/op (avarage)",item)
show_plots(dram_threads,optane_threads,[1,2,4,8],"dram_threads","optane_threads","micros/op (avarage)",item)
show_plots(dram_reads,optane_reads,[100,1000,10000,100000,1000000],"dram_reads","optane_reads","micros/op (avarage)",item)
show_plots(dram_keysize,optane_keysize,[1,2,4,8,16],"dram_keysize","optane_keysize","micros/op (avarage)",item)
show_plots(dram_valuesize,optane_valuesize,[1,2,4,8,16,32,64,128],"dram_valuesize","optane_valuesize","micros/op (avarage)",item)
show_plots(dram_readwritepercent,optane_readwritepercent,[10,20,30,40,50,60,70,80,90],"dram_readwritepercent","optane_readwritepercent","micros/op (avarage)",item)
show_plots(dram_txsize,optane_txsize,[1,2,4,8,16],"dram_txsize","optane_txsize","micros/op (avarage)",item)
show_plots(dram_disjoint,optane_disjoint,[0,1],"dram_disjoint","optane_disjoint","micros/op (avarage)",item)
show_plots(dram_dbsize,optane_dbsize,[1,2,3],"dram_dbsize","optane_dbsize","throughput [MB/s]",item)
show_plots(dram_keynum,optane_keynum,[100,1000,10000,100000,1000000],"dram_keynum","optane_keynum","throughput [MB/s]",item)
show_plots(dram_threads,optane_threads,[1,2,4,8],"dram_threads","optane_threads","throughput [MB/s]",item)
show_plots(dram_reads,optane_reads,[100,1000,10000,100000,1000000],"dram_reads","optane_reads","throughput [MB/s]",item)
show_plots(dram_keysize,optane_keysize,[1,2,4,8,16],"dram_keysize","optane_keysize","throughput [MB/s]",item)
show_plots(dram_valuesize,optane_valuesize,[1,2,4,8,16,32,64,128],"dram_valuesize","optane_valuesize","throughput [MB/s]",item)
show_plots(dram_readwritepercent,optane_readwritepercent,[10,20,30,40,50,60,70,80,90],"dram_readwritepercent","optane_readwritepercent","throughput [MB/s]",item)
show_plots(dram_txsize,optane_txsize,[1,2,4,8,16],"dram_txsize","optane_txsize","throughput [MB/s]",item)
show_plots(dram_disjoint,optane_disjoint,[0,1],"dram_disjoint","optane_disjoint","throughput [MB/s]",item) - 根据我选取的参数变量表,绘制出对应的平均响应时间曲线以及吞吐量的折线图。接下来针对每一个参数进行分析:
- dbsize(数据库大小):
- 响应时间:基本上响应时间在1GB的时候是最短的,之后便趋于稳定。
- 吞吐量:基本上吞吐量在1GB的时候是最大的,之后便趋于稳定。
- 特殊情况:readwhilewriting的响应时间随着数据库的增大变长
- keynum(键值数量):
- 响应时间:随着键值数量的增加,都是1byte到4byte会有一个上升接着就依次递减。
- 吞吐量:随着键值数量的增加,1byte到4byte会有一个下降随后就一次依次递增。
- 特殊情况:在readrandomwriterandom时,随着键值的增加,响应时间逐渐下降最后几乎不变,吞吐量逐渐递增然后几乎不变。
- threads(线程数):
- 响应时间:随着线程数的增加,响应时间也随之增加。
- 吞吐量:随着线程数的增加,吞吐量也随之增加。
- reads(读操作的数量):
- 响应时间:几乎没有影响。
- 吞吐量:几乎没有影响。
- 特殊情况:readrandomwriterandom会随着读操作数量的增加突然急剧减少最后趋于稳定,感觉可能是建立起了cache?
- keysize(键值大小):
- 响应时间:随着键值大小逐渐增大,响应时间逐渐上升并趋于稳定。
- 吞吐量:随着键值大小逐渐增大,吞吐量逐渐减小并趋于稳定。
- valuesize(value大小):
- 响应时间:随着valuesize逐渐增大,响应时间逐渐增大并趋于稳定。
- 吞吐量:随着valuesize逐渐增大,吞吐量逐渐增大。
- readwritepercent(读写操作比例):
- 响应时间:基本保持稳定。
- 吞吐量:基本上保持稳定。
- 特殊情况:readwrandomwriterandom测试会随着读操作比例的上升响应时间降低。
- txsize(每个线程的一个事务操作的条目数):
- 响应时间:保持稳定。
- 吞吐量:保持稳定。
- disjoint(是否处理不相交的键值的集合):
- 响应时间:基本保持稳定。
- 吞吐量:基本保持稳定。
- 特殊情况:readwhilewriting时如果处理相交的键值集合会导致响应时间上升,readrandomwriterandom如果处理相交键值集合会导致响应时间下降,吞吐量上升。
- dbsize(数据库大小):
在阿里云上租了一台服务器拿来跑测试(一小时1.8真的是贵)
测试环境介绍
- CPU:Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz 双核心
- 内存大小:8GB
- 傲腾内存:31.5GB
- 通过ndctl进行管理,把傲腾内存挂载为ext4文件系统,使用dax模式进行访问
- 选择的引擎:cmap
横向对比分析
- dbsize(数据库大小):
- 响应时间:基本上optane延迟是dram的1.3~1.8倍
- 吞吐量:基本上dram吞吐量是optane的1.3~1.4倍
- 特殊情况:readwhilewriting两者的带宽几乎没有差距,随机读写时数据库大小为1GB时两者差别都不明显。
- keynum(键值数量):
- 响应时间:顺序写入的延迟在key数目为100时延迟最长,之后就只比内存慢20%左右。随机写入时,两者延迟相近,但是随着写入数目的增加就逐渐稳定,optane大约是内存的1.5倍。
- 吞吐量:基本上都是键值数量很少的时候两者比较接近,但是随着键值数的增加保持在1.5倍左右。
- 特殊情况:readwhilewriting两者的延迟几乎相近,readrandomwriterandom两者都是一开始延迟很高后面都变得很小了。
- threads(线程数):
- 响应时间:基本上optane是内存的1.5倍。二者都会随着线程数的增加延迟增加。
- 吞吐量:基本上内存是optane的1.3~1.8倍
- reads(读操作的数量):
- 响应时间:基本上optane是内存的1.5倍。
- 吞吐量:基本上内存是optane的1.3~1.5倍
- 特殊情况:readwhilewriting,readrandomwriterandom的情况两者延迟几乎相近。
- keysize(键大小):
- 响应时间:小键大小两者都比较接近。最后随着键大小增大,optane是dram的1.5倍左右。
- 吞吐量:键比较小的时候比较接近,但是随着键大小的增加内存大约是optane的1.5倍。
- 特殊情况:readwhilewriting两者延迟和吞吐量比较接近。
- valuesize(value大小):
- 响应时间:optane基本上一直维持在内存的1.5倍
- 吞吐量:明显二者都是和value大小成线性关系
- 特殊情况:很明显在16~32byte这个阶段二者延迟都有一个很明显的上升但是这个阶段的吞吐量几乎没有变化。
- readwritepercent(读写操作比例):
- 响应时间:基本上optane都是内存的1.3~1.8倍。
- 吞吐量:基本上都是内存是optane的1.3~1.8倍。
- 特殊情况:readwhilewriting两者基本上都差不多。
- txsize(每个线程的一个事务操作的条目数):
- 响应时间:基本上optane都是内存的1.3~1.8倍。
- 吞吐量:基本上都是内存是optane的1.3~1.8倍。
- 特殊情况:readwhilewriting基本上二者差不多。
- disjoint(是否处理不相交的键值的集合):
- 响应时间:optane是内存的1.5倍
- 吞吐量:基本上都是内存是optane的1.3~1.8倍。
- dbsize(数据库大小):
下面结合cmap源码对测试结果进行分析
- cmap引擎介绍:
- cmap是一款基于concurrenthashmap的数据库引擎,它使用了libmemobj.h中的concurrentmap数据结构作为map。同时,作者使用了斐波那契散列来实现hash值的均匀分布,对于斐波那契散列,建议阅读链接
- cmap测试结果分析:
- 通过上面实验做出的测试结果,我们可以总结出现有的cmap引擎的优点和缺陷:
- 优点:
- 实现了一致性,多线程等功能。
- 通过上面实验做出的测试结果,我们可以总结出现有的cmap引擎的优点和缺陷:
- cmap引擎介绍:
阿里云部署傲腾内存指南
做出来的分析图,需要的请自行下载
网上ucsb也做了一份测试报告链接