- Cephfs学习笔记
什么是Cephfs
- Cephfs所在的位置
- 下面给出了文件系统存储区别于块存储的结构区别
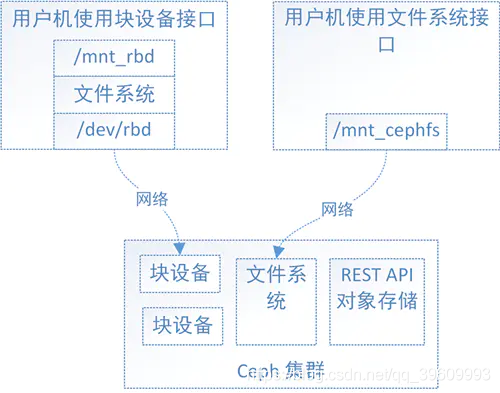
用户可以在块设备上创建xfs文件系统,也可以创建ext4等其他文件系统。如上图,Ceph集群实现了自己的文件系统来组织管理集群的存储空间,用户可以直接将Ceph集群的文件系统挂载到用户机上使用。
- 下面给出了文件系统存储区别于块存储的结构区别
- Cephfs存储方式的优势
- 之前介绍了cephfs相比于使用rbd的块存储方式的区别,相比于rbd块存储,cephfs对于共享性有着更好的支持
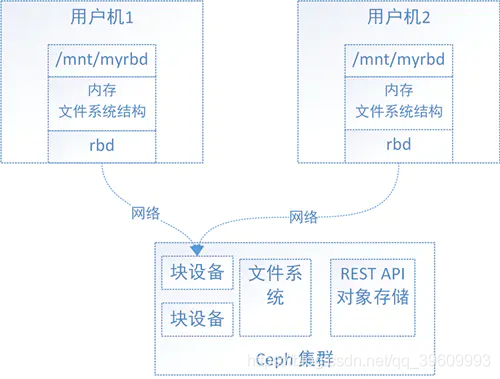
- 对于Ceph的文件系统接口,如上图,文件系统的结构状态是维护在远端Ceph集群中的,Ceph文件系统同时挂载到了用户机1和用户机2,当往用户机1的挂载点写入数据后,远端Ceph集群中的文件系统状态结构随之更新,当从用户机2的挂载点访问数据时会去远端Ceph集群取数据,由于远端Ceph集群已更新,所有用户机2能够获取最新的数据。
- 之前介绍了cephfs相比于使用rbd的块存储方式的区别,相比于rbd块存储,cephfs对于共享性有着更好的支持
Cephfs的mds
mds状态
mds在ceph系统正常运行时会有几种状态,下面介绍这几种常见的状态:- up:activate
这个状态代表了现在的mds处在工作状态并且正在被文件系统使用 - up:standby
这个状态代表了现在的mds处在灾备状态但是作为备用的mds - up:standby_replay
当一个up:activate的节点发生了fail,有一个standby_replay的mds节点replay实时日志,这样它就有元数据的热缓存,在负责这个 rank 的守护进程失效时,会帮助standby节点更快的接管activate节点。注意到这个状态的mds节点不能用来接管任何一个发生fail的activate节点,只能记录它对应activate的mds节点。一个rank只能够有一个standby_replay节点。
以下的状态基本上是不常见的或者是中间状态:
- up:boot
这个状态基本上是不可见的,因为monitor会很快就把MDS设置为对应的状态 - up:creating
这个状态表示mds正在构建一些pre-rank元数据并且进入mds集群来创建一个新的rank - up:starting
这个状态表示了mds正在重启一个被停止了的rank,这会打开关联的per-rank元数据并进入mds集群 - up:stopping
当一个rank被停止,monitor会指挥activate状态的目的是节点进入up:stopping状态。这个状态mds不会接受任何新的客户端连接请求,把所有的子树迁移到其他的rank中去,清空自己的元数据日志,如果是自己是rank0,就会直接中断所有的客户端连接并关机。 - up:replay
这个状态代表现在的mds正在接管fail的节点,修复日志和元数据 - up:resolve
mds在up:replay状态时由于cephfs有多种ranks才进入这种状态,这个mds会处理所有没有提交的MDS间操作。文件系统之中必须所有的等级都处于这个状态才能继续操作。如果发生no rank可能会发生fail从而导致up:replay - up:reconnect
MDS 从up:replay或进入此状态up:resolve。此状态是请求来自客户端的重新连接。任何与 thisrank 有会话的客户端都必须在此期间重新连接,可通过mds_reconnect_timeout. - up:rejoin
MDS 从up:reconnect进入此状态。在这种状态下,MDS 正在重新加入 MDS 集群缓存。特别是,重新建立元数据上的所有 MDS 间锁定。如果没有已知的客户端请求被重放,MDS 直接从这个状态变为up:active。
- up:activate
mds主从切换流程
- 用户手动发起主从切换fail。
- active mds手动信号,发起respawn重启。
- standby mds收到信号,经过分布式算法推选为新主active mds。
- 新主active mds 从up:boot状态,变成up:replay状态。日志恢复阶段,他将日内容读入内存后,在内存中进行回放操作。
- 新主active mds 从up:replay状态,变成up:reconnect状态。恢复的mds需要与之前的客户端重新建立连接,并且需要查询之前客户端发布的文件句柄,重新在mds的缓存中创建一致性功能和锁的状态。
- 新主active mds从up:reconnect状态,变成up:rejoin状态。把客户端的inode加载到mds cache。(耗时最多的地方)
- 新主active mds从up:rejoin状态,变成up:active状态。mds状态变成正常可用的状态。
- recovery_done 迁移完毕。
- active_start 正常可用状态启动,mdcache加载相应的信息
mds核心组件分析
- MDSDaemon(MDS守护线程)
- Beacon:是mds向monitor的心跳组件,如果mds发送的心跳信号没有从monitor端收到回应,就说明网络通信出现了问题,mds会建立一个消息队列等待所有消息被处理
- Messenger:mds的网络通信组件
- MonClient:连接monitor的组件
- MDSMap:用来处理MDSMap的组件
- Objecter:连接osd的组件
- MDSRank:MDS的核心组件
- MDSRankDispatcher:mds的核心组件
- MDSDaemon(MDS守护线程)
mds源码分析
ceph_mds.cc
- 该文件位于/src目录下,里面的main函数包括了mds的工作流程
- 首先创建守护进程,创建一个messenger实例来处理消息,绑定需要连接的client的地址和端口号。
- 获取monitor map, 启动mds,messenger消息队列等待,当mds彻底关闭之后消息队列关闭
MDSDaemon.h && MDSDaemon.cc
- 该文件位于/src/mds目录下,里面包括了mds守护进程怎么启动以及mds怎么从一个standby状态被分配到mds集群中
int MDSDaemon::init():这个函数包括了初始化Monclient,初始化mgrclient,初始化SaftTimer,初始化Beacon,重置tick等等bool MDSDaemon::ms_dispatch(Message *m):这个函数专门用来处理各种消息。如果mds处于shutdown状态,不处理消息,优先处理daemon message,如果发现不是核心态消息,重新给rank发送消息bool MDSDaemon::handle_core_message(Message *m):这个函数会被ms_dispatch调用,用来具体处理高优先级的消息(从MON,MDS,OSD发来的消息)void MDSDaemon::ms_handle_accept(Connection *con):连接上accept。void handle_mds_map(const cref_t<MMDSMap> &m);:每一个standby状态下的mds会等待monitors分配一个在mds集群中的位置,这里实现的过程就是mds会监听并等待接受一个新的mds map,这个函数包括怎么接受一个core message的mds map以及解码一系列操作。最后还会有一系列关于mds状态切换的代码MDSRank.h && MDSRank.cc
- 概念补充:rank是元数据工作负载在多个 MDS ( ceph-mds ) 守护进程之间共享的方式。ranks是一次可能处于活动状态的 MDS 守护进程的最大数量。每个 MDS 处理分配给该等级的文件系统元数据的子集。每个 MDS 守护进程最初都没有等级。
void MDSRankDispatcher::init():初始化,从配置文件中读取log配置以及更新log配置,并创建log。处最后创建progressthread进程。void MDSRankDispatcher::tick():重置heartbeat超时时间,防止因为超时被monitor kill,flush所有的log,唤醒progress_thread进程,根据mdsmap的状态,如果是active或者是stopping状态就周期性,清空cache,client_lease,log等信息,如果是reconnect,replay等状态也调用对应的方法。void MDSRankDispatcher::shutdown():关闭定时器,MDSlog,finisher,mdcache,objecter,monclient回调op_tracker的shutdown回调函数,关闭messengerbool MDSRank::_dispatch(const cref_t<Message> &m, bool new_msg):专门用来处理laggy状态FSMap.h && FSMap.cc
- fsmap类是一个mdsmap类的集合,里面有三个成员:
1
2
3fs_cluster_id_t fscid = FS_CLUSTER_ID_NONE;
MDSMap mds_map;
MirrorInfo mirror_info;
- 该文件位于/src目录下,里面的main函数包括了mds的工作流程