- 论文阅读文档整理
ATC
Disaggregating Persistent Memory and Controlling Them Remotely: An Exploration of Passive DisaggregatedKey-Value Stores
- 研究简介
- 现在的分布式PM系统主要采用了非分解式架构,其中集群中的每一个服务器都是会被本地服务器和远程服务器上的应用程序使用的。
- PM架构
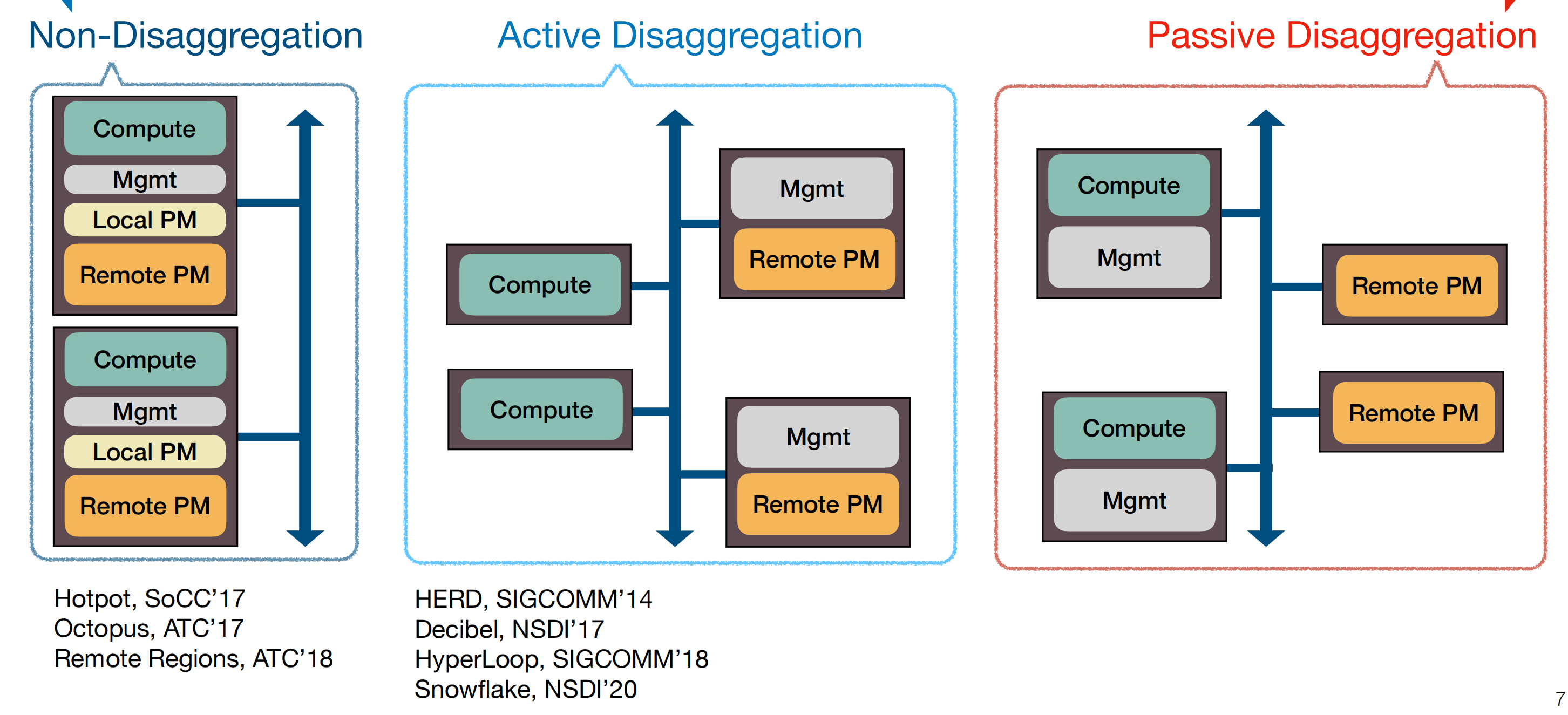
- 第一种架构每一个服务器都要进行计算,存储等功能,并且每个节点都需要有一个pm管理层用来管理pm。
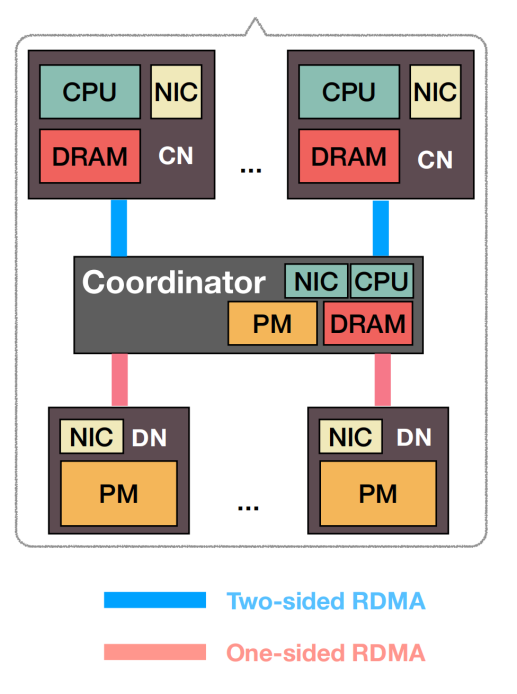
- 第二种架构把计算节点和存储节点分开,左侧的节点是专门用来计算的节点,右侧的节点是专门用来存储的节点,构建分解PM系统的一种方法是会在数据所在的位置主动管理数据,通过数据节点共同定位数据并进行管理,但是对于每一个存储节点必须要求有强大的处理能力来维持高带宽网络,并且需要存储节点完全支持PM
- 第三种架构是把第二种架构中原本放在存储节点的管理层放到了计算节点上。为了实现第三种方式,作者考虑了三种可能的实现方法
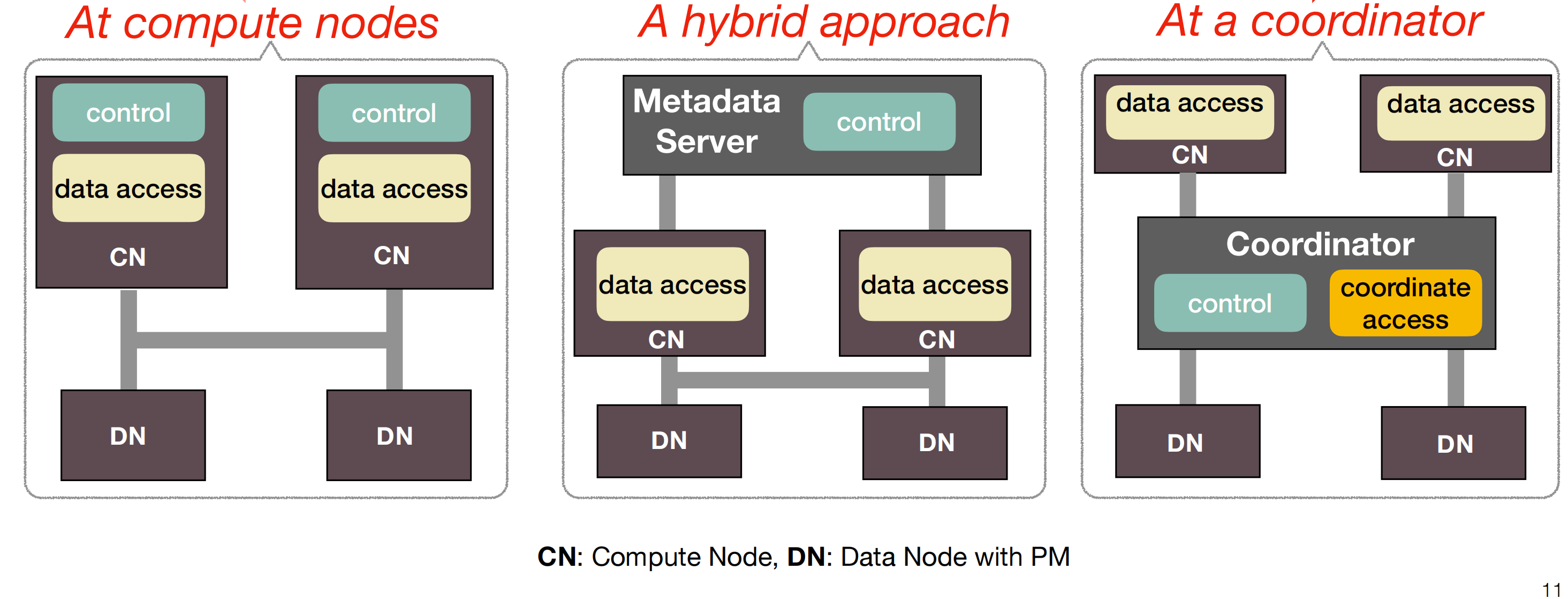
- 第一种控制层和数据获取层全部都放在计算节点上
- 第二种是加入一个控制管理服务器专门用来数据的中转
- 第三种是让计算节点可以直接访问存储节点,但是把数据控制层放在了metadata server上
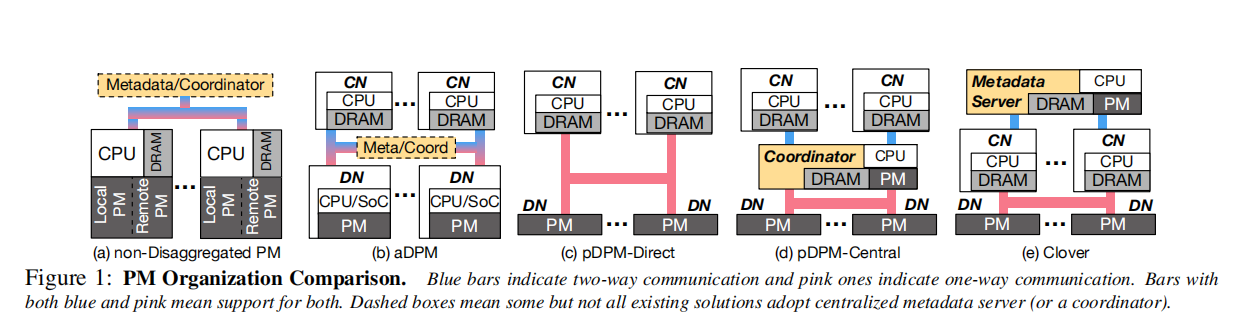
- 本文中构造的分解PM架构会直接把存储节点视为不执行任何数据处理或者管理任务的节点,这就意味着对于每个数据节点的访问必须来源于网络,缺点是会导致并发写入这种操作变得更加困难。数据节点不能在本地执行任何管理任务和元数据操作,每个数据节点可以独立失效
- 为了完成作者的三种设计,我们必须知道要在什么地方执行数据和元数据的操作。作者根据上面谈到的三种方案设计出了三种实现方法。
- 第一种方法是让客户端/计算节点直接通过单向网络和数据节点进行通信。在构建评估了一个真正的pDPM-direct键值存储系统后,发现并不能有效的完成数据协调,当有相同的数据发生并发读写时,性能和伸缩性都很差。
- 第二种解决方案,作者提出在计算节点集群和数据节点集群中添加一个中央服务器进行协调,这种虽然是一个解决方法,但是中央服务器又成为了一个新的性能瓶颈。
- 第三种解决方案,最终作者设计出了clover系统架构,分离出数据和元数据的操作,通过不同的通信机制来访问,并且采用了不同的管理策略。数据在数据节点上,元数据在元数据服务器上,计算节点通过单边网络执行所有的元数据和控制操作。
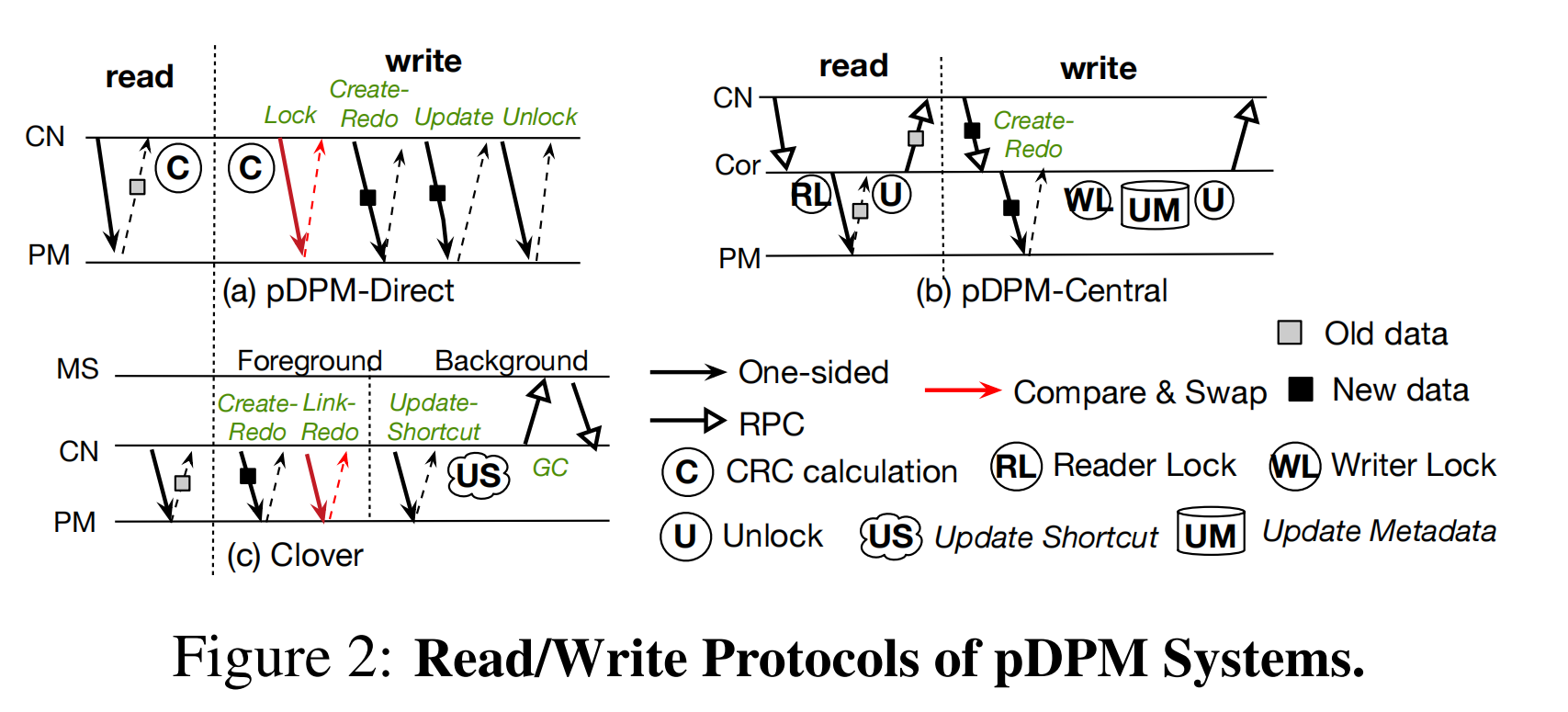
- pdpm-direct架构设计介绍
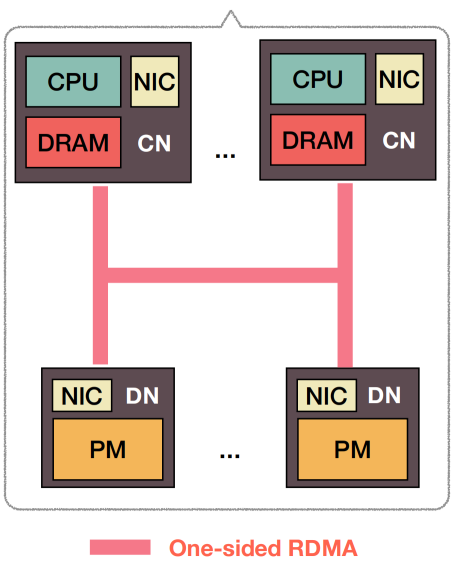
- 写操作
- 首先计算节点先获取需要写入数据的锁,接着把需要写入的数据和checksum写进kventry的uncommited空间中,然后再把需要写入的数据和checksum写入到kventry的commited空间中,最后再完成解锁操作,一共是4个RTT
- 读操作
- 直接从存储节点中读取并进行校验计算,一个RTT外加上一个checksum计算时间
- 写操作
- pdpm-central架构设计介绍
- 写操作
- 首先计算节点向coordiator发送一个写入操作,中间的coordiator维护一个mapping table把数据写入存储节点的过程中给mapping table上锁最后更新元数据然后返回信号给计算节点
- 读操作
- 首先计算节点向coordiator发送一个读操作请求,给mapping table上锁,然后访问存储节点获取数据并返回给计算节点,最后解锁。
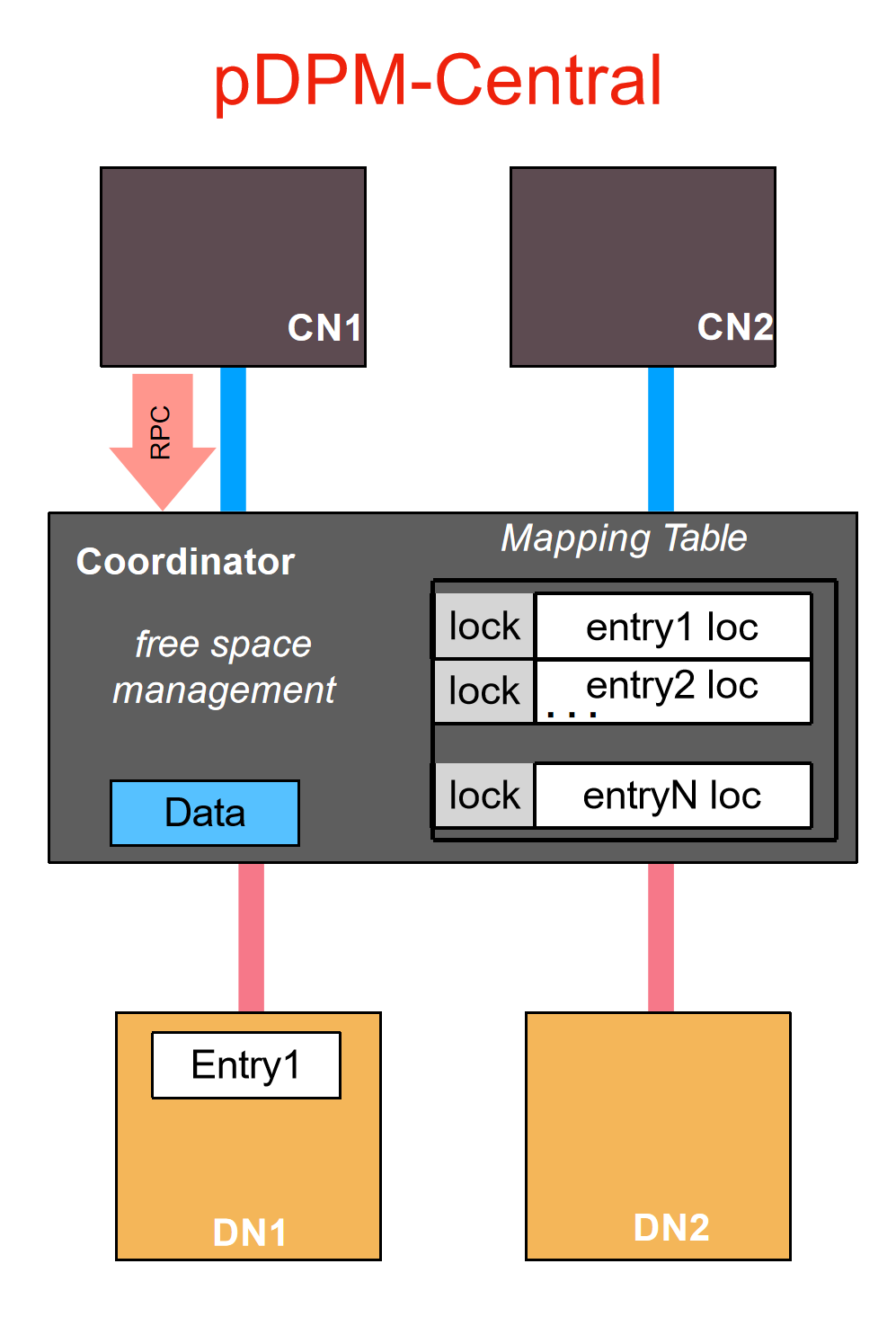
- 首先计算节点向coordiator发送一个读操作请求,给mapping table上锁,然后访问存储节点获取数据并返回给计算节点,最后解锁。
- 写操作
- clover架构设计介绍
- 数据层面
- 支持多个metadata server,每一个metadata server都会存储其需要负责的元数据条目,计算节点端会缓存热的数据条目,计算节点缓存支持FIFO和LRU替换算法
- 为了实现无锁,快速和可伸缩的读取和写操作。我们允许在数据节点中实现一个数据条目的多个提交版本,并且把这些版本组成一个链,空指针指示该版本是最新的一个版本
- 计算节点在第一次访问数据时从metadata server端获取链表的表头,然后在计算节点的本地缓存该表头。这里计算节点中的光标指向的是数据缓冲区版本的头节点,然后通过单边RDMA继续读取下一个版本直到下一个版本为NULL值代表当前版本是最新版本,最后计算节点会更新光标指向最新的版本节点
- 当计算节点上的光标指向的不是最新的版本时,慢慢遍历整个版本链的方法显然是不可取的,时间开销太大。作者想到了可以使用快捷方式的办法直接指向每个数据条目的最新版本,metadata server 存储了所有快捷方式的位置,当计算节点第一次访问数据条目的时候会首先从metadata server找到对应的快捷方式的位置,并进行缓存
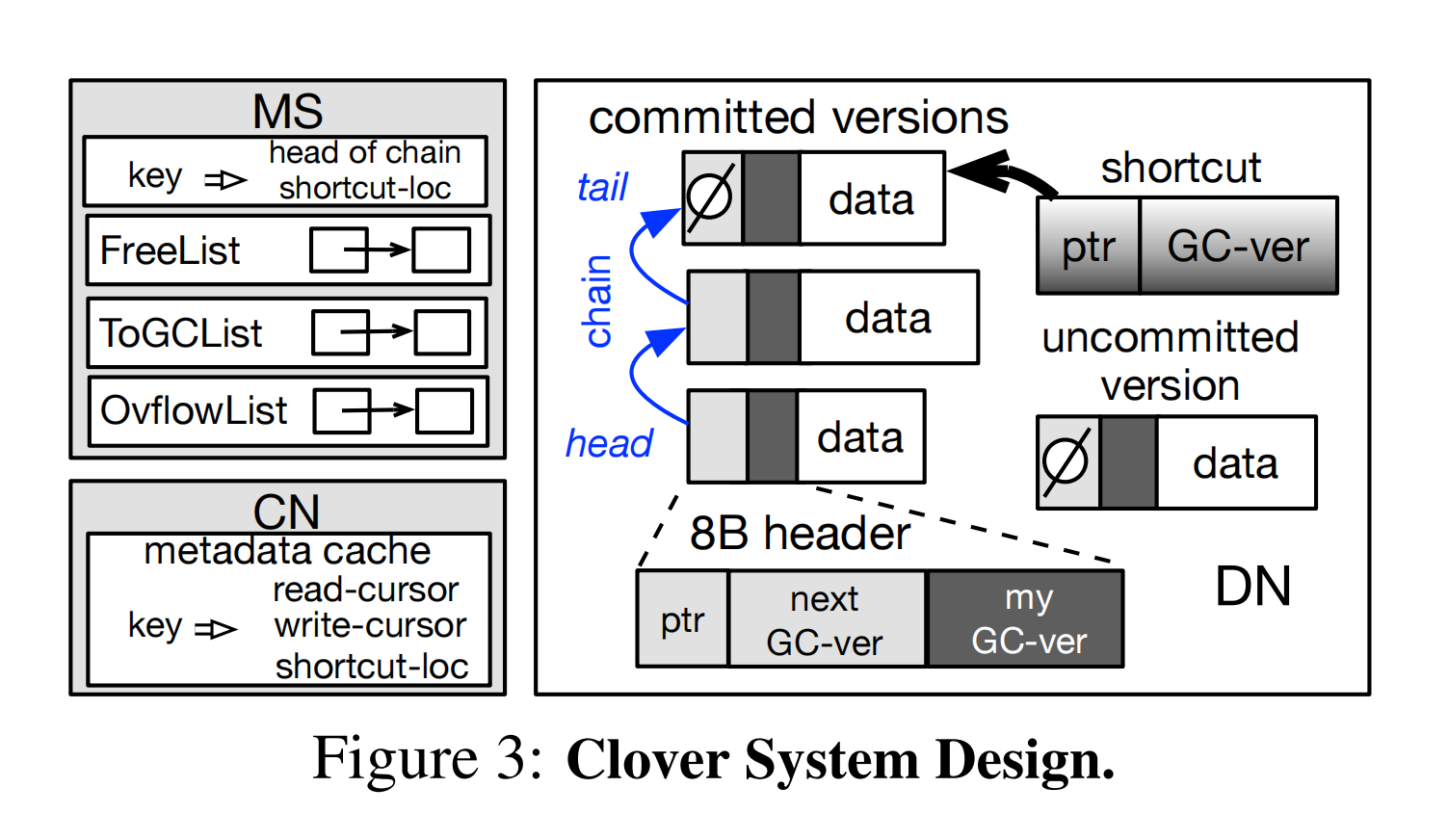
- 当一个计算节点发出链状读取和快捷方式读取,哪一种方式读取完成的越快便先返回哪一个结果。作者并没有使用快捷方式完全替换链读取。因为快捷方式的更新是在后台异步更新的,可能更新速度没有链访问更快clover从来不覆盖现有的数据条目。
- 如果需要编写数据条目,计算节点首先选择metadata server提前分配空闲的数据节点空间,然后把数据写入到缓冲区中,计算节点把新数据链接链接到条目版本的尾部。(使用链行走到达尾端),最后计算节点使用单边RDMA更新条目的快捷方式,保证快捷方式指向新的数据版本,并保证计算节点的光标也指向了最新的版本。
- 这个设计结构的优势就是不会发生读者影响写者,还可以保证读者只能看到已经提交的版本。当写入的操作被提交之后,计算节点也会退出旧版本的数据条目,会把缓冲区进行重新回收。为了改善性能并且尽量减少和metadata server端的通信计算节点在后台发送异步分批处理的retire请求,作者还避免了使用超时和epoch的垃圾回收机制。
- 除非发生两个或两个以上的计算节点对同一个文件进行写操作时才会发生性能下降的情况。
- 控制层面
- 计算节点和metadata server端实现的是双向通信,下面作者设计了metadata server功能,完成最佳的性能和扩展性
- 空间分配:当clover进入写模式,对数据节点的空间分配有着很高的要求。这里作者会通过metadata server把所有的数据节点的空闲空间打包成块。每一个块对应了相同大小的数据缓冲区。不同的数据块可以有不同的大小,每一个计算节点不会在每一次写入数据之前都请求一个新的空闲空间,而是一次性向后台的metadata server请求多个空间块。这种方法很有效,当然这个过程中也可以实现存储节点的负载均衡。
- 垃圾回收装置:clover的只是添加链数据结构保证了写入速度很快。作者专门设计了一种垃圾回收机制,不涉及任何数据移动或者向数据节点进行通信,同时也最小化了metadata server和计算节点之间的通信。metadta server通过把回收的空间放入一个自由列表(freelist见上图)来处理从计算节点传入的retire请求。当计算节点请求更多的空闲缓冲区,就可以直接从metadata server的freelist中获取。
- 作者提出了两种技术来解决strawman垃圾回收机制(这种机制会导致在回收了缓冲区后计算节点缓存的cursor无效导致链访问失败)。
- 第一种技术是:metadata server在回收数据缓冲区后不清除数据缓冲区的头或内容(这回保证链访问能够继续)。
- 第二种技术是我们给每个数据缓冲区添加一个垃圾回收版本号。当一个数据缓冲区被回收之后,metadata server会增加版本号。
- 当这个被回收的缓冲区作为空闲空间分配给计算节点,meatdata server会提供GC版本以及缓冲区的位置,当计算节点使用该空间进行新的数据写入之前,数据节点上该空间的内容包括了旧的数据和旧的版本号。计算节点会通过其缓存cursor的GC版本和从DN中读取的GC版本进行比较,如果不匹配,计算节点就会丢弃掉读取的内容,并且把光标置为无效。我们的GC版本的方法不仅避免了MS使CNs上的光标缓存无效,而且还消除了MS在GC期间访问dn的需要。
- 以上的设计还不能保证read的原子性。如果read访问太长,有可能会读取到被GC后又被重新写的结点。提出一个类似FaRM里的操作。因为上述的情况下,需要两个RTT才能完成,一个RTT用来提交,一个RTT用来MS发布新空间。那么当read操作超过两个RTT后,就打断它。
- 使用版本号,就存在溢出的风险。尤其是RDMA verb操作大小有限制。所以CN没办法知道当前看到的DN上的版本号,是否匹配了自己cache的,还是溢出后的。解决方法是:MDS维护一个Ovflow List。当MDS自加GC version发现溢出时,就把这次释放的空间,放在ovflowlist里。放在这个list里的空间,会等待一个特定时间长度$ T_e $后才移入freelist。计算节点在$T_e$时间内未访问的entry上,把所有的缓存下来的位置全部删除。为了同步MS和CN的时间,metadata server会在每个$T_e$给CN发一个包。
- 数据可靠性以及负载均衡
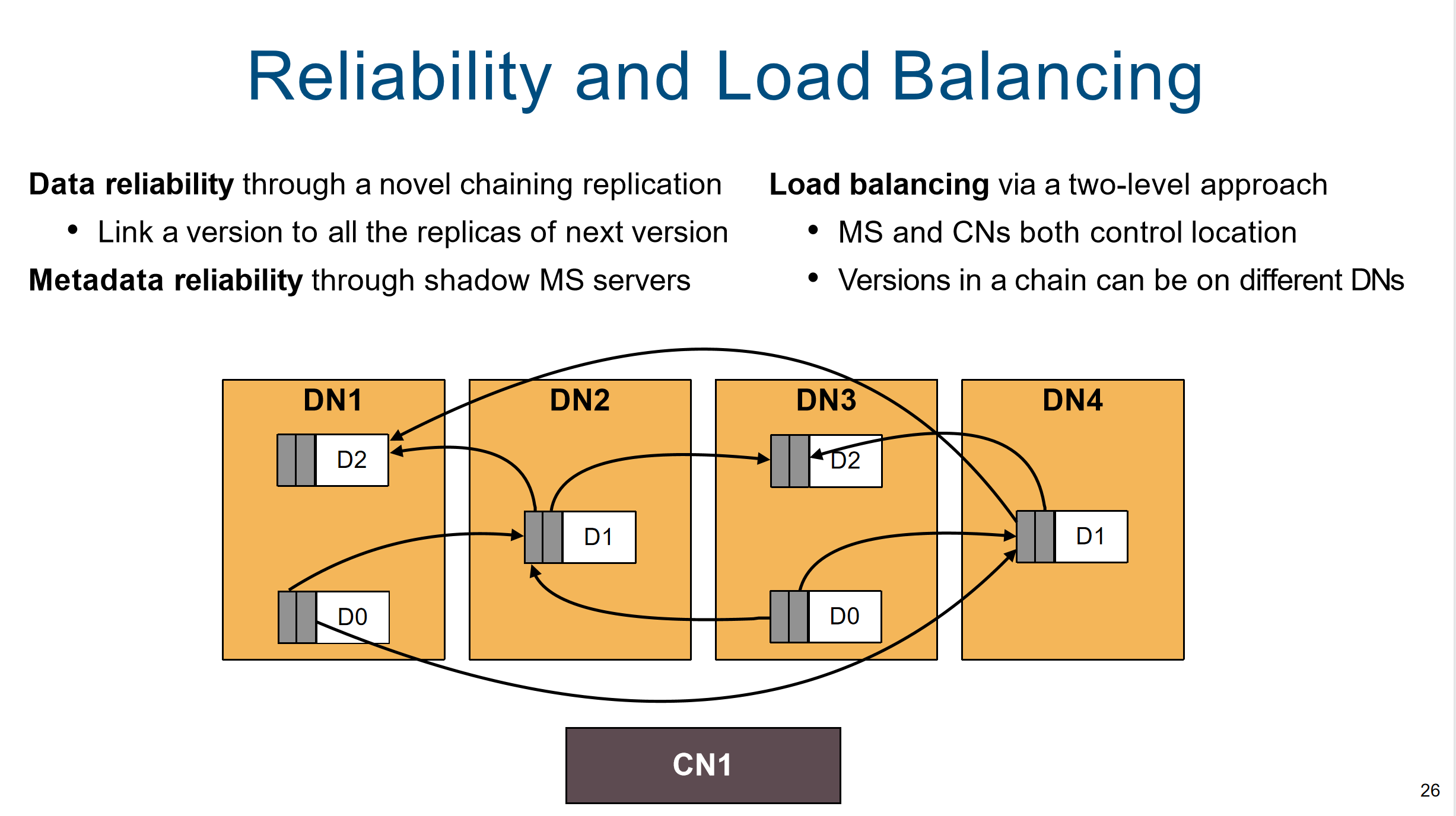
- MDS靠同步部分元数据(key和对应的位置)的镜像节点来保证可靠性。一旦挂了,就上镜像节点,然后镜像节点通过备份的部分元数据,重建其他元数据。
- 数据层面
- 性能对比结果
- 读写延迟对比
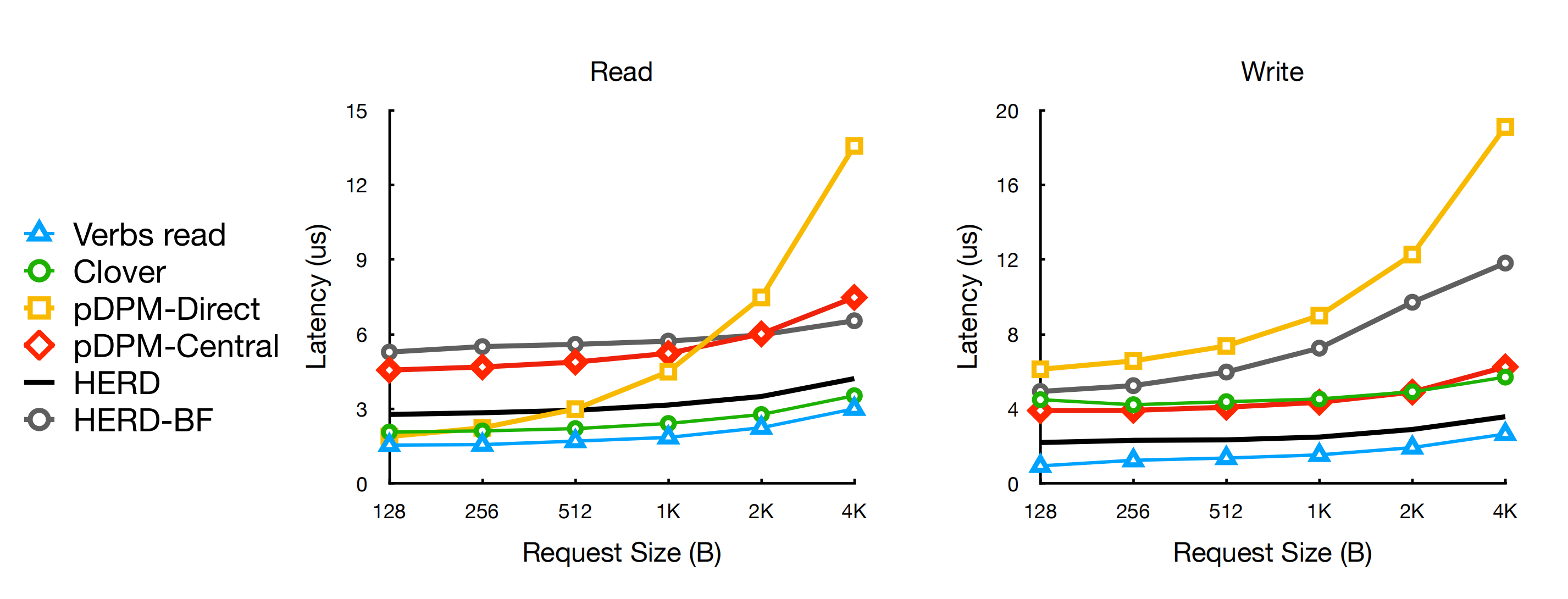
- ycsb test
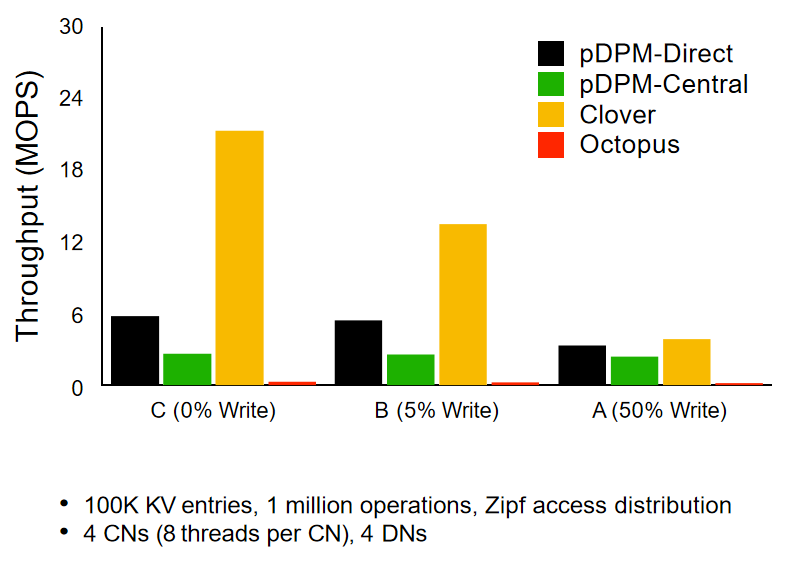 在吞吐量的指标上的对比
在吞吐量的指标上的对比
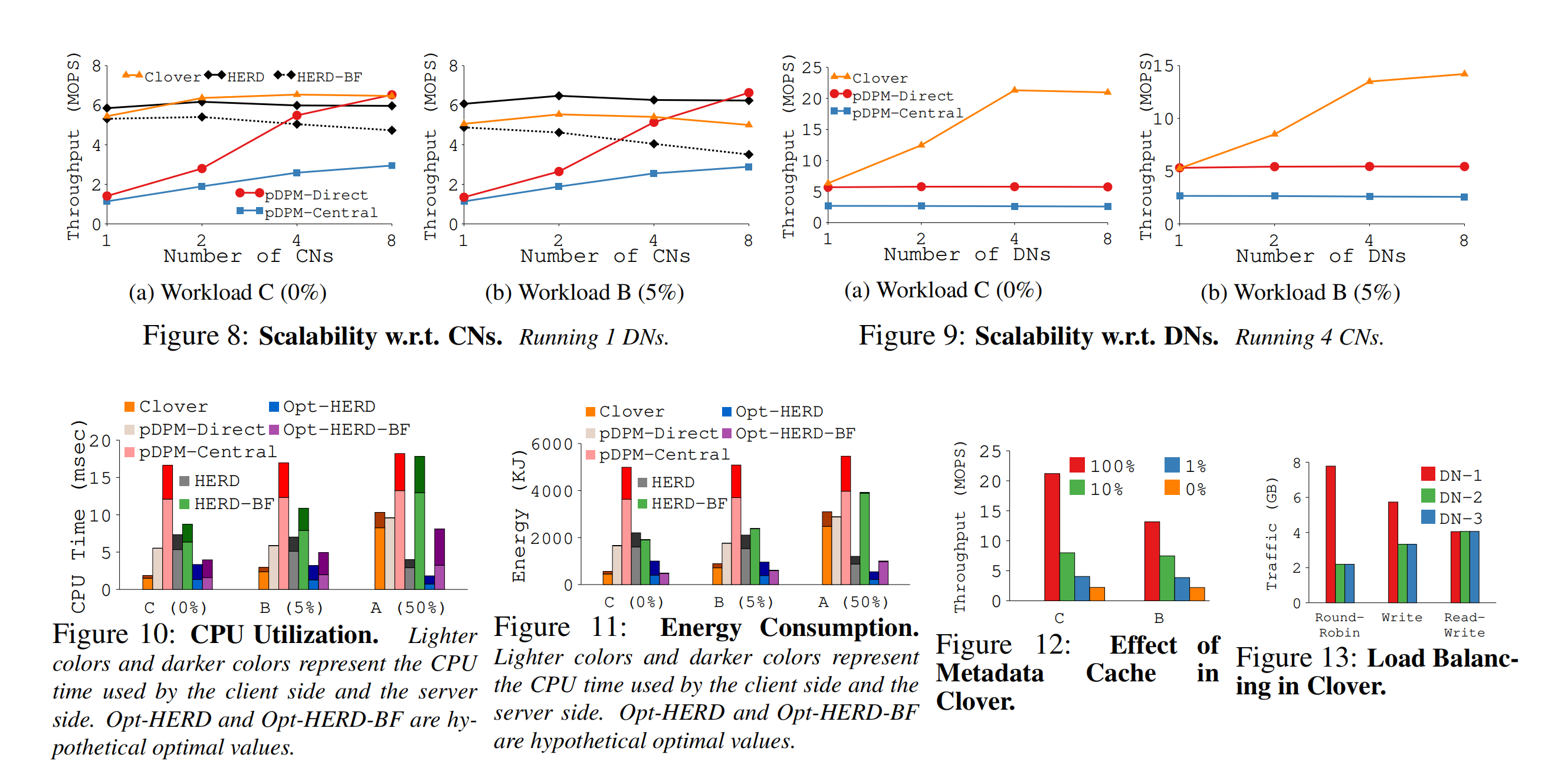
可以看到,write操作需要2 RTT的Clover在写比例上升后,性能明显下滑。到50%的比例时,99分位的操作就需要6个RTT才能完成。Octopus表现不好,不过他也不是为了键值存储设计的,实验是在上面在跑了一层MongoDB来支持键值存储的。条形越高吞吐量越好 - 在CPU使用率、功耗等指标上,都有一定的优势。以及随着CN数量增加,吞吐量的变化。
- 三种模型的读写协议流程
- 读写延迟对比
Octopus: an RDMA-enabled Distributed Persistent Memory File System
- 摘要:
非易失性内存 (NVM) 和远程直接内存访问 (RDMA) 在存储和网络硬件方面提供了极高的性能。然而,现有的分布式文件系统将文件系统和网络层严格隔离,并且繁重的分层软件设计使高速硬件没有得到充分利用。在本文中,我们提出了一个支持 RDMA 的分布式持久内存文件系统 Octopus,通过紧密耦合 NVM 和 RDMA 功能来重新设计文件系统内部机制。对于数据操作,Octopus 直接访问共享的持久内存池以减少内存复制开销,并在客户端主动获取和推送数据以重新平衡服务器和网络之间的负载。对于元数据操作,Octopus 引入了自我识别的 RPC,用于文件系统和网络之间的即时通知,以及一个高效的分布式事务机制来保证一致性。评估表明,八达通为大型 I/O 实现了几乎原始带宽,并且性能比现有分布式文件系统好几个数量级。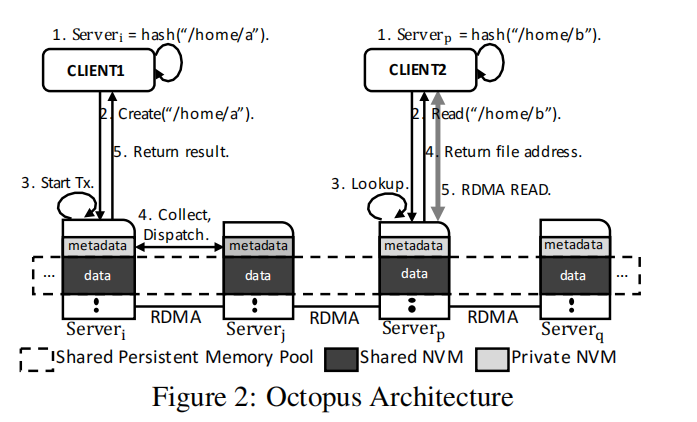
- Octopus是为一组配备非易失性存储器和rdma网络的服务器而设计的。Octopus由两部分组成:客户端和数据服务器,它没有集中的元数据服务器,元数据分布在不同的数据服务器上。在Octopus中,文件以基于哈希的方式分发到数据服务器,如上图所示。一个文件的元数据和数据块在同一个数据服务器中,但是它的父目录和它的兄弟目录可能被分发到其他服务器。在每个服务器中,数据区域在整个集群中共享,以便进行远程直接数据访问,而元数据区域出于一致性的原因保持私有。
First Responder: Persistent Memory Simultaneously as High Performance Buffer Cache and Storage
- 摘要:
Persistent Memory (PM) 是一种具有良好特性的新介质,可以极大地提高存储 I/O 性能。虽然已经开发了新的基于 PM 的文件系统来利用 PM,但在将 PM 介质与传统存储介质(如 SSD 和 HDD)完全集成方面,大多数工作都没有成功。我们介绍了 First Responder (FR),这是一种利用 PM 有益特性的方法,同时利用现代和成熟的文件系统,例如为传统存储设备开发的 Ext4。从概念上讲,FR 很像缓冲区缓存,但涉及的内容更多,例如在故障情况下保持一致性和提供轻量级管理开销。FR 带来多重好处。首先,我们保留现有文件系统的成熟度,允许在部署传统文件系统的环境中部署 FR。第二,可以使用这些文件系统支持的传统存储设备,从而轻松将 PM 与传统存储集成。最后,FR 允许以接近 PM 设备延迟的顺序文件系统语义。通过英特尔 DC PMM 的实验评估,我们表明当以缓存形式使用时,FR 的性能可以超过 Ext4 9 倍以上,同时提供持久的有序文件系统语义,而 Ext4 则不能。我们还表明,当用作典型文件系统的一部分时,性能与 NOVA 和 Ext4-DAX 相当。同时提供持久的有序文件系统语义,而 Ext4 则不能。
FAST
Reaping the performance of fast NVM storage with uDepot
摘要:
许多应用程序需要低延迟键值存储,通常使用由 DRAM 支持的键值存储来满足这一要求。然而,最近,与传统 SSD 相比,基于新型 NVM 技术的存储设备提供了前所未有的性能。可以提供这些设备性能的键值存储将为加速应用程序和降低成本提供许多机会。然而,为较慢的 SSD 或 HDD 构建的现有键值存储无法充分利用此类设备。在本文中,我们介绍了 uDepot,这是一种自下而上构建的键值存储,可提供基于 NVM 块的快速设备的性能。uDepot 精心设计以避免低效率,使用两级索引结构动态调整其 DRAM 占用空间以匹配插入的项目,并采用新颖的基于任务的 IO 运行时系统来最大化性能,使应用程序能够使用快速 NVM 设备发挥他们的全部潜力。作为嵌入式存储,uDepot 的性能在吞吐量和延迟方面几乎与快速 NVM 设备的原始性能相匹配,同时可跨多个设备和内核进行扩展。作为服务器,uDepot 在 YCSB 基准测试中明显优于针对 SSD 的最先进商店。最后,通过在 uDepot 之上使用 Memcache 服务,我们证明了构建在 NVM 存储设备上的数据服务可以以更低的成本提供与基于 DRAM 的同类产品相同的性能。事实上,我们使用 uDepot 构建了一个云 Memcache 服务,该服务目前在公共云中作为实验性产品提供。
Rethinking File Mapping for Persistent Memory
研究简介
- 作者介绍了四种文件映射方法的设计和实现,并且探索了他们对pm各种优化。作者在strata文件系统中实现了这些方案,针对页面缓存,映射结构大小,io大小,存储设备利用率,碎片化,隔离机制和文件访问模式如何影响这些文件映射方法的性能进行了实验分析。
- 最后作者得出的结论是hashfs是性能最好的映射方法,主要是因为其低内存开销和利用了pm随机读取和插入时的低延迟
- 作者得出结论,使用传统的页面缓存对于pm优化的文件映射没有提供帮助,并且pm优化的存储结构不能简单的放到pm文件系统中。
- 文件映射:把文件中的逻辑偏移量映射到底层设备上的物理位置的操作。
- 难点一:碎片化。当一个文件的数据分布在存储设备上的非连续物理位置时,就会发生碎片。当一个文件不能在设备的单个连续区域中分配时,或者当文件增长并且所有相邻的块都被分配给其他文件时,就会发生这种情况。随着文件系统的老化,碎片是不可避免的,并且可能很快发生。许多传统的文件系统使用紧凑的文件映射结构,如extent树,它可以使用单个区段条目映射大范围的相邻文件位置。碎片化导致位置变得不连续,映射结构变得更大,这会增加搜索和插入时间。碎片化的另一个后果是减少了顺序访问。碎片导致数据结构位置在设备上的分离,这导致设备上额外的、随机的IO。这会降低IO性能,特别是在PM设备上。在文件映射过程中,碎片是不可避免的,因为碎片整理并非总是可行或可取的
- 难点二:引用局部性:可以使用访问文件时的引用位置来减少文件映射开销。本地访问通常通过缓存之前的进程和预取相邻的进程来加速。操作系统页面缓存和CPU缓存可以透明地实现这一点。通过记住先前查找的元数据位置并预取下一次查找的位置,我们可以隐藏部分文件映射结构遍历开销以用于具有局部性的访问。
- 难点三:映射结构的大小。映射结构大小:文件映射结构的总大小是可用文件系统空间的一部分,这是衡量文件映射效率的重要指标。理想情况下,文件映射结构只消耗一小部分可用空间,为实际的文件数据存储留下空间。此外,映射结构的大小会影响保留在缓存中的数据量。
- 难点四:并发。确保并发修改不影响一致性可能是昂贵的操作,且可伸缩性有限。在per-file映射中,只在改变文件大小操作时才会修改映射结构,因此使用读写锁即可。然而在全局映射范围中,由于多个文件并发的追加和截断争用的可能性更大。
- 优点一:崩溃一致性
- 优点二:页面缓存。页面缓存管理并不是一项挑战,因为在pm优化的文件系统上,绕过页面缓存的文件映射结构总是更有效的。
四种pm文件映射设计
现在描述四种pm优化的文件映射方法的设计,首先是两种传统的、per-file的映射方法及其PM优化,然后是两种全局映射方法。
- Traditional Per-file Mapping
- 在大多数传统文件系统中,文件映射是每个文件执行的。每个文件都有自己的弹性映射结构,随着结构需要维护的映射数量的增加而增加或减少。映射结构是通过一个独立的、固定大小的inode表找到的,索引是文件的inode号。每个文件映射通常提供高空间局部性,因为单个文件的所有映射都被组合在一个结构中,这个结构通常被缓存在操作系统页面缓存中。在映射结构中,相邻的逻辑块通常表示为相邻的映射ping,从而导致更高效的顺序文件操作。并发访问对于每个文件映射方法来说是一个小问题,因为每个文件访问模式受到限制。物理块分配是通过一个单独的块分配器执行的,它是在我们的测试床文件系统中使用红黑树实现的。
- 遇到的难点:每个文件的映射结构必须支持调整大小,这可能是一个昂贵的操作。由于它们需要增长和收缩,每个文件映射结构有多个间接层次,因此每个映射操作都需要更多的内存引用。碎片破坏了这些结构的紧凑布局,并增加了间接访问和内存访问的数量,从而加剧了开销。
- Extent Tree:这是一种经典的Per-file映射结构,但在现代pm优化的文件系统中仍在使用。区段树是包含extent的b-tree,extent将文件逻辑块映射到物理块,以及指示映射所代表的块数量的字段。区段也可以是间接的,指向进一步的区段树节点而不是文件数据块。为了执行查找,在每个节点上执行二分查找,以确定哪个条目包含所需的物理块。该搜索在区段树的每一层上执行,如下图所示。
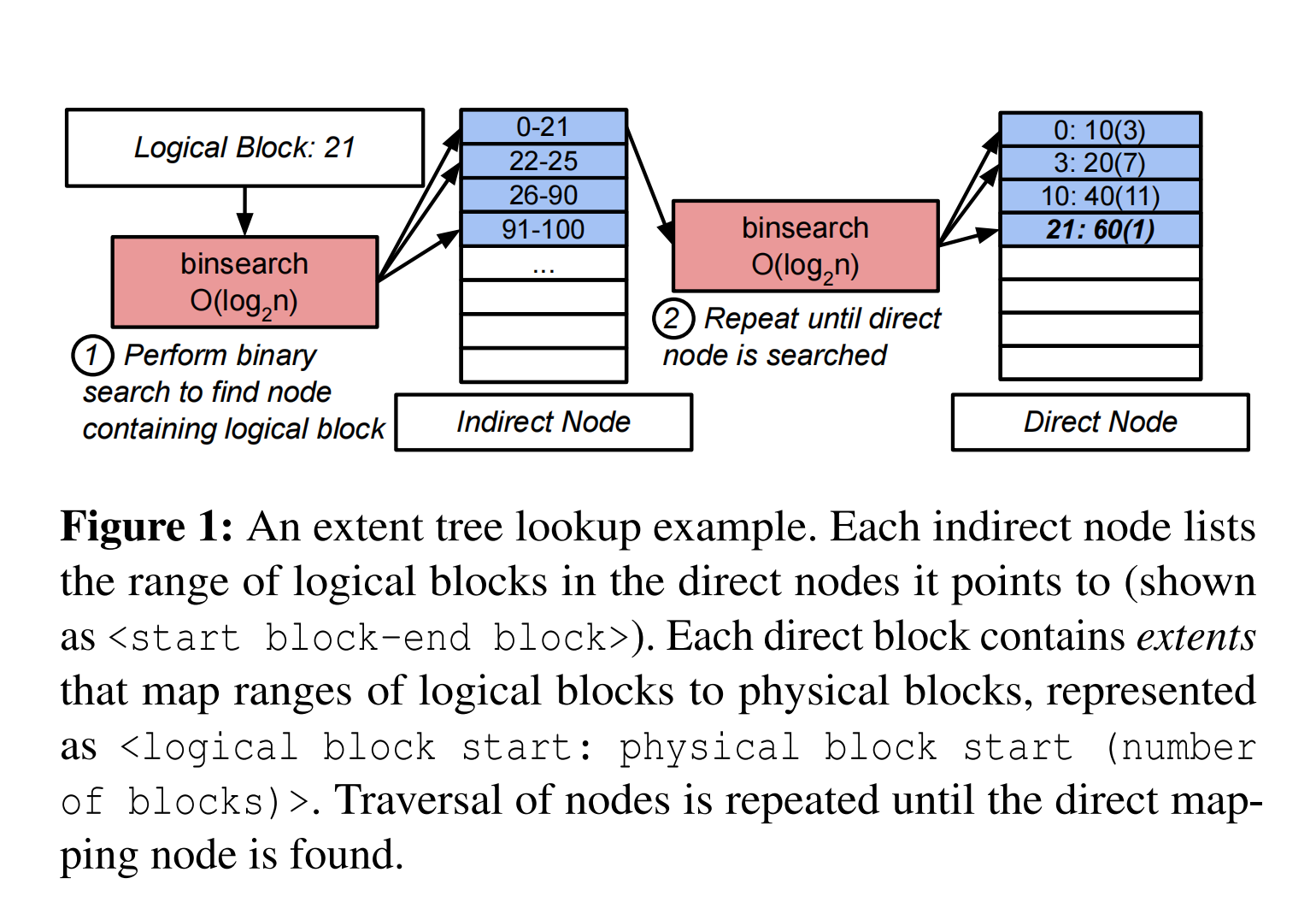 区段树具有四种映射结构的最紧凑表示,因为多个映射可以合并到一个区段中,从而导致较小的结构大小。然而,区段树需要很多内存访问,因为它们必须在区段树的每一层执行二进制搜索,以找到最终的映射。游标可以简化搜索,但仅限于通过结构和重复块访问的顺序扫描。
区段树具有四种映射结构的最紧凑表示,因为多个映射可以合并到一个区段中,从而导致较小的结构大小。然而,区段树需要很多内存访问,因为它们必须在区段树的每一层执行二进制搜索,以找到最终的映射。游标可以简化搜索,但仅限于通过结构和重复块访问的顺序扫描。 - Radix Tree:基数树是另一种流行的按文件映射结构,如图所示。 基数树中的每个节点占用设备上的物理块(通常为 4KB)。
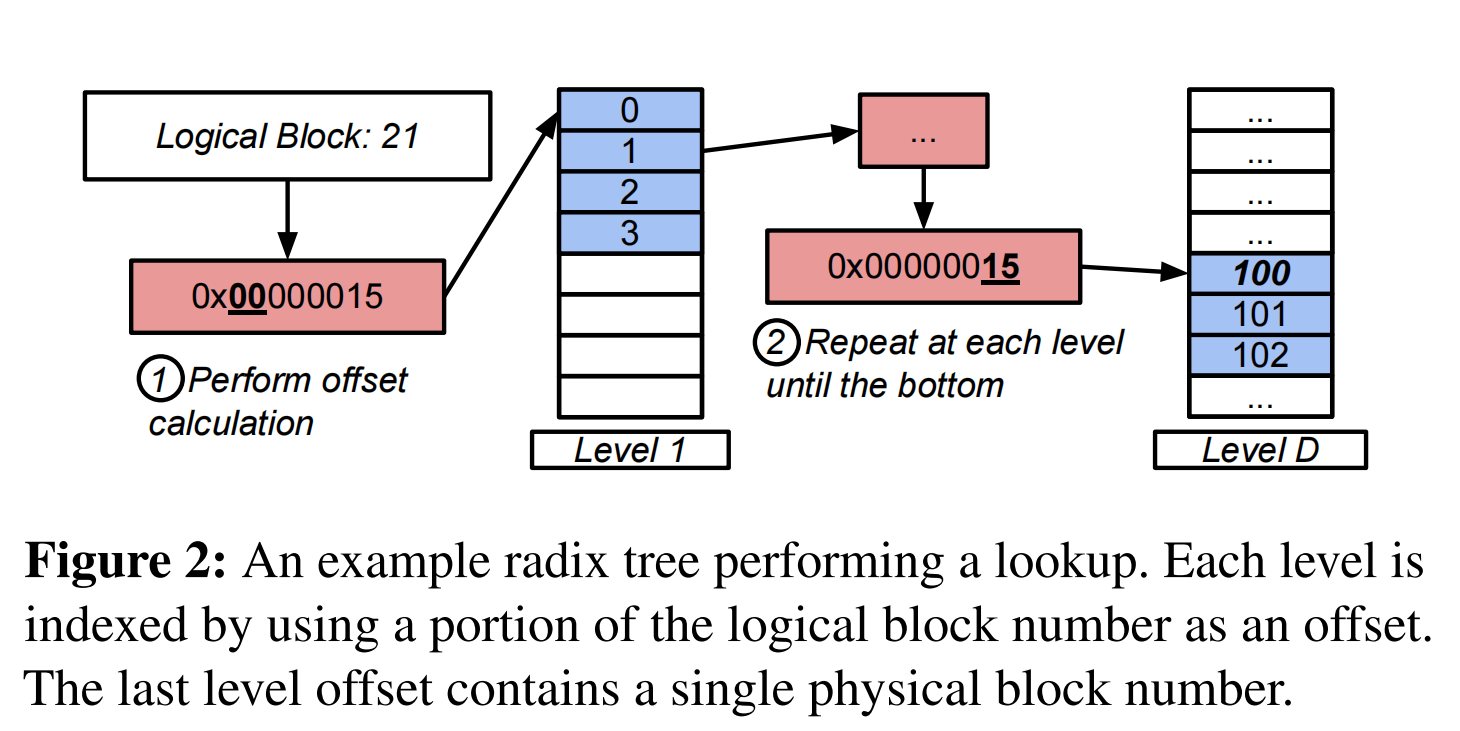 查找从顶级节点开始解析逻辑块号的前 N 位。 第二级节点解析接下来的 N 位,依此类推。 基数树动态增长和收缩以使用包含映射数量所需的尽可能多的级别(例如,N < 9 的文件只需要一个单级树)。 最后一级节点包含到物理块的直接映射。 为了加速顺序扫描,DRAM 中的游标通常用于缓存树中搜索的最后一个位置。 由于每个指针只是一个 64 位整数(一个物理块号),因此可以通过 CPU 的原子指令来保证一致性。 通过首先在撤消日志中记录修改来提供调整大小的一致性。
查找从顶级节点开始解析逻辑块号的前 N 位。 第二级节点解析接下来的 N 位,依此类推。 基数树动态增长和收缩以使用包含映射数量所需的尽可能多的级别(例如,N < 9 的文件只需要一个单级树)。 最后一级节点包含到物理块的直接映射。 为了加速顺序扫描,DRAM 中的游标通常用于缓存树中搜索的最后一个位置。 由于每个指针只是一个 64 位整数(一个物理块号),因此可以通过 CPU 的原子指令来保证一致性。 通过首先在撤消日志中记录修改来提供调整大小的一致性。
缺点:基数树不如范围树紧凑,通常需要更多的间接性。 因此,树遍历平均需要更长的时间,因为基数树比extent树增长得更快。 然而,基数树具有计算上最简单的映射操作——一系列偏移计算,每一层树只需要一次内存访问。因此,它们通常比区段树执行更少的内存访问,因为区段树对每个区段树节点进行O(log(N))内存访问(二分搜索),以找到要遍历的下一个节点。
- Extent Tree:这是一种经典的Per-file映射结构,但在现代pm优化的文件系统中仍在使用。区段树是包含extent的b-tree,extent将文件逻辑块映射到物理块,以及指示映射所代表的块数量的字段。区段也可以是间接的,指向进一步的区段树节点而不是文件数据块。为了执行查找,在每个节点上执行二分查找,以确定哪个条目包含所需的物理块。该搜索在区段树的每一层上执行,如下图所示。
PM-specific Global File Mapping
- Global Cuckoo Hash Table:这个哈希表使用布谷鸟哈希,这意味着每个条目使用两个不同的哈希函数进行哈希两次。对于查找,最多需要咨询两个地点。对于插入,如果两个潜在的插槽都满了,插入算法选择一个现有条目,并将其移动到备用位置,直到没有更多的冲突。我们在这种设计中使用布谷鸟哈希,而不是线性探测,以避免在冲突样例中不得不穿越潜在的长链冲突,将找到单个索引所需的内存访问次数限制为2。
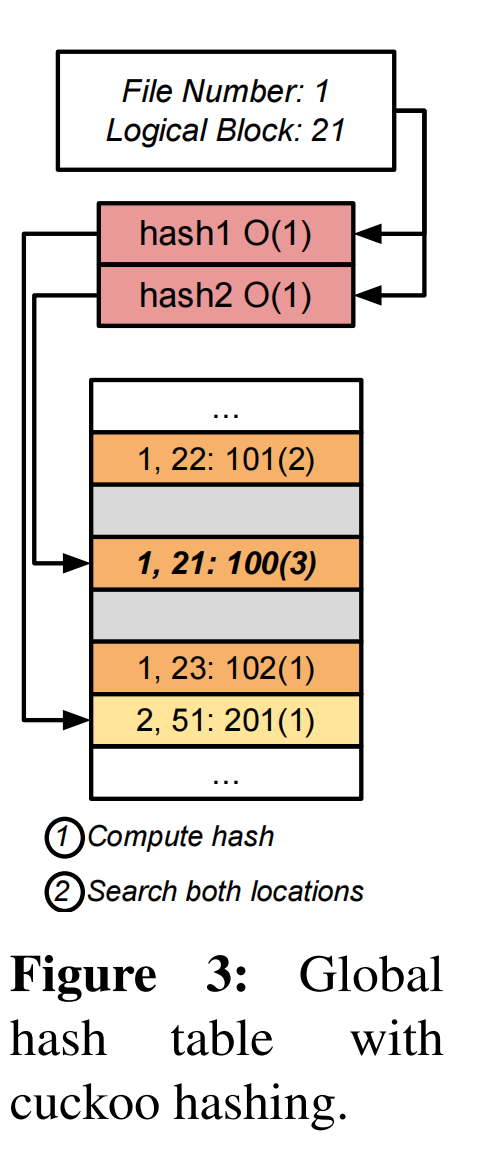
- hashfs:
- HashFS被划分为一个元数据区域和一个文件数据区域。物理块存储在文件数据区域中,该区域从fileDataStart开始。查找首先解析到元数据区域。对应的物理块位置是从元数据区域中条目的偏移量计算出来的。例如,如果<inum=1, lblk=21>的hash值解析为元数据区域的offset i,则对应的物理块的位置为(fileDataStart +i×blockSize), blockSize = 4KB。
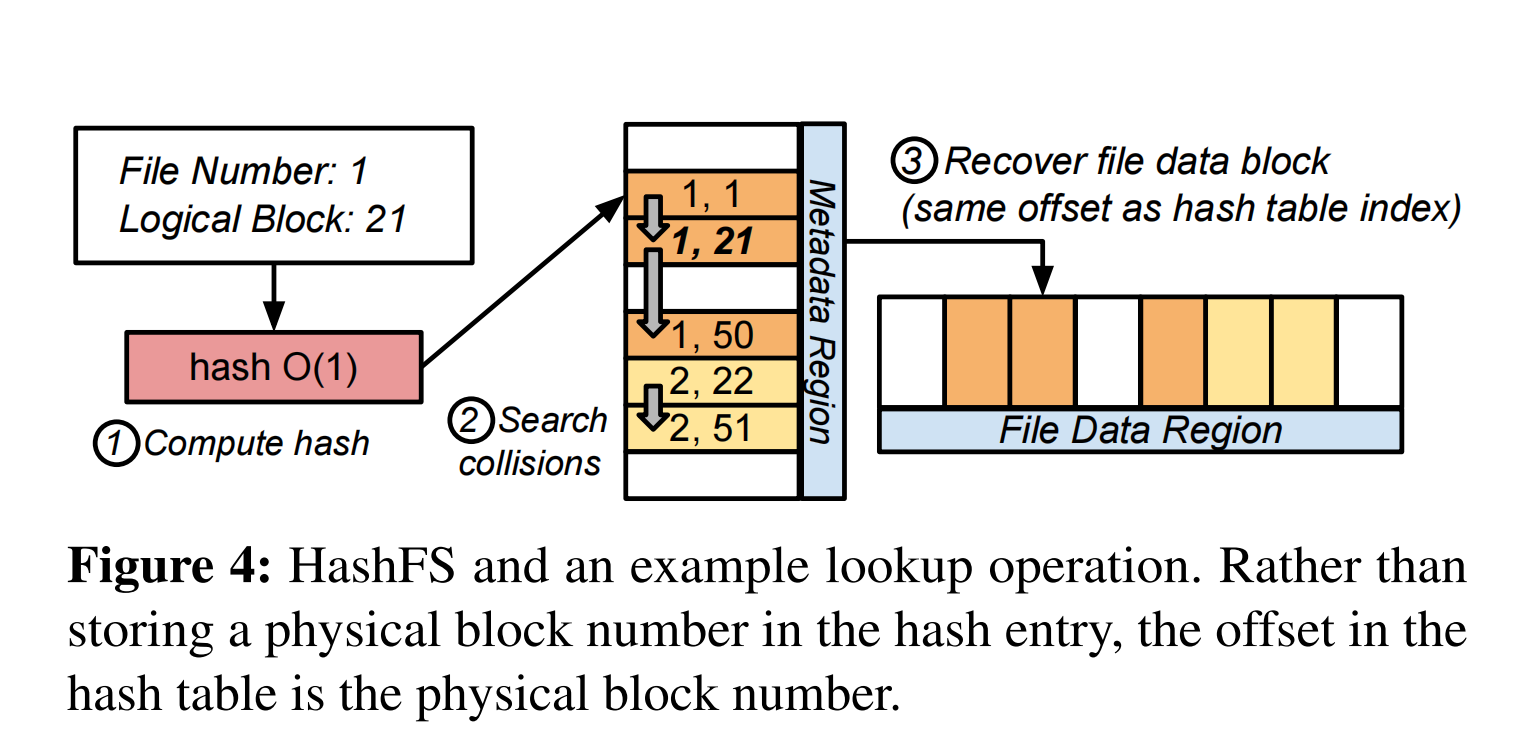
- 该表没有任何范围的节点,而是提供了逻辑块和物理块之间的纯一对一映射。这在文件系统中使用每4kb数据块8字节的恒定空间,总空间开销为PM的0.2%。该方案的另一个优点是哈希表条目非常简单——组合inodenumber和logical block,适合一个64位整数。因此,可以简单地通过内在的原子的比较和交换来保证一致性。
- 线性探测的一个优点是,冲突的条目存储在相邻的位置,通过避免PM缓冲区中的丢失,减少了搜索冲突的开销。此外,与cuckoo哈希不同,线性探测永远不会重新定位条目(即重哈希),它保留了元数据条目的索引和文件数据块之间的对应关系。
- HashFS被划分为一个元数据区域和一个文件数据区域。物理块存储在文件数据区域中,该区域从fileDataStart开始。查找首先解析到元数据区域。对应的物理块位置是从元数据区域中条目的偏移量计算出来的。例如,如果<inum=1, lblk=21>的hash值解析为元数据区域的offset i,则对应的物理块的位置为(fileDataStart +i×blockSize), blockSize = 4KB。
- Global Cuckoo Hash Table:这个哈希表使用布谷鸟哈希,这意味着每个条目使用两个不同的哈希函数进行哈希两次。对于查找,最多需要咨询两个地点。对于插入,如果两个潜在的插槽都满了,插入算法选择一个现有条目,并将其移动到备用位置,直到没有更多的冲突。我们在这种设计中使用布谷鸟哈希,而不是线性探测,以避免在冲突样例中不得不穿越潜在的长链冲突,将找到单个索引所需的内存访问次数限制为2。
SPHT: Scalable Persistent Hardware Transactions
- 摘要:
随着字节可寻址持久内存(PM)的出现,最近有许多工作解决了如何使用现成的硬件事务内存系统来实现持久事务内存的问题。使用英特尔傲腾 DC PM,我们首次在文献中展示了实验结果,突出了最先进方法的几个可扩展性瓶颈,迄今为止仅通过 PM 仿真对其进行了评估。我们通过提出 SPHT(ScalablePersistent Hardware Transactions)来解决这些限制,这是一种创新的 PersistentTransactional Memory,它利用了一组旨在增强事务处理和恢复期间可扩展性的新颖机制。我们展示了 SPHT 在 STAMP 上将吞吐量提高了 2.6 倍,并在日志重放阶段实现了 2.8 倍的加速比与最先进的解决方案相比。
Scalable Persistent Memory File System with Kernel-Userspace Collaboration
- 摘要:
我们介绍了 Kuco,一种新颖的直接访问文件系统架构,其主要目标是可扩展性。Kuco 利用三种关键技术——协作索引、两级锁定和版本读取——将耗时的任务(例如路径名解析和并发控制)从内核转移到用户空间,从而避免内核处理瓶颈。在 Kuco 上,我们介绍了 KucoFS 的设计和实现,然后通过实验证明 KucoFS 在广泛的实验中具有出色的性能;重要的是,KucoFS 在元数据操作方面比现有文件系统的扩展性好一个数量级,并充分利用设备带宽进行数据操作。
SOSP
SplitFS: Reducing Software Overhead in File Systems for Persistent Memory
- 摘要:
我们提出了 SplitFS,这是一种用于持久内存 (PM) 的文件系统,与最先进的 PM 文件系统相比,它显着降低了软件开销。SplitFS 在用户空间库文件系统和现有内核 PM 文件系统之间提出了一种新颖的职责划分。用户空间库文件系统通过拦截 POSIX 调用、内存映射底层文件以及使用处理器加载和存储服务读取和覆盖来处理数据操作。元数据操作由内核 PM 文件系统 (ext4 DAX) 处理。SplitFS 引入了一种称为重新链接的新原语,以有效地支持文件追加和原子数据操作。SplitFS 提供了三种一致性模式,不同的应用可以选择,互不干扰。与 NOVA PM 文件系统相比,SplitFS 最多可减少 4 倍的软件开销,与 ext4 DAX 相比可减少 17 倍。在许多微基准测试和应用程序(例如运行 YCSB 基准测试的 LevelDB 键值存储)上,与 ext4 DAX 和 NOVA 相比,SplitFS 将应用程序性能提高了 2 倍,同时提供了类似的一致性保证。